Trilio Previews Agentless Data Protection Tool for Kubernetes
Trilio has made available a technical preview of Trilio Vault, an agentless approach to backup and recovery that can run natively on Kubernetes.
Company CEO David Safaii says Trilio Vault will make it possible for IT teams to apply incremental point-in-time backup schemas against any storage target they prefer. That approach is critical because it will enable lT organizations to address the ephemeral nature of containers, which are frequently ripped and replaced without any notice provided to the IT operations team.
In addition, Trilio announced TrilioVault has been certified to run on Red Hat OpenShift, which is built on top of Kubernetes, extending its support beyond Red Hat OpenStack and Red Hat Virtualization.
Safaii says Trilio is now applying an approach proven in OpenStack environments to Kubernetes. That multi-tenant approach enables both the application owner and IT operations teams to employ the same schema to data protection without having to worry about whether any data might be overwritten by either party, he says. That goal is achieved via support for the QEMU Copy-On-Write (QCOW2) file format that only writes data to a disk from a virtual machine when it’s needed. Safaii also notes Trilio Vault eliminates the need to buy a separate data deduplication tool because that capability is built into the way Trilio Vault stores data.
IT organizations can also leverage the point-in-time capabilities enabled by Trilio Vault to manage version control across multiple applications running on multiple Kubernetes clusters, Safaii says.




Finally, Trilio plans to make Trilio Vault available via either a graphical user interface (GUI) for storage administrators or an application programming interface (API). In addition, Safaii says Trilio Vault will be integrated with tools for configuring and managing Kubernetes clusters, such as the open source Helm project being overseen by the Cloud Native Computing Foundation (CNCF), in addition to providing access to Kubernetes Operator software.
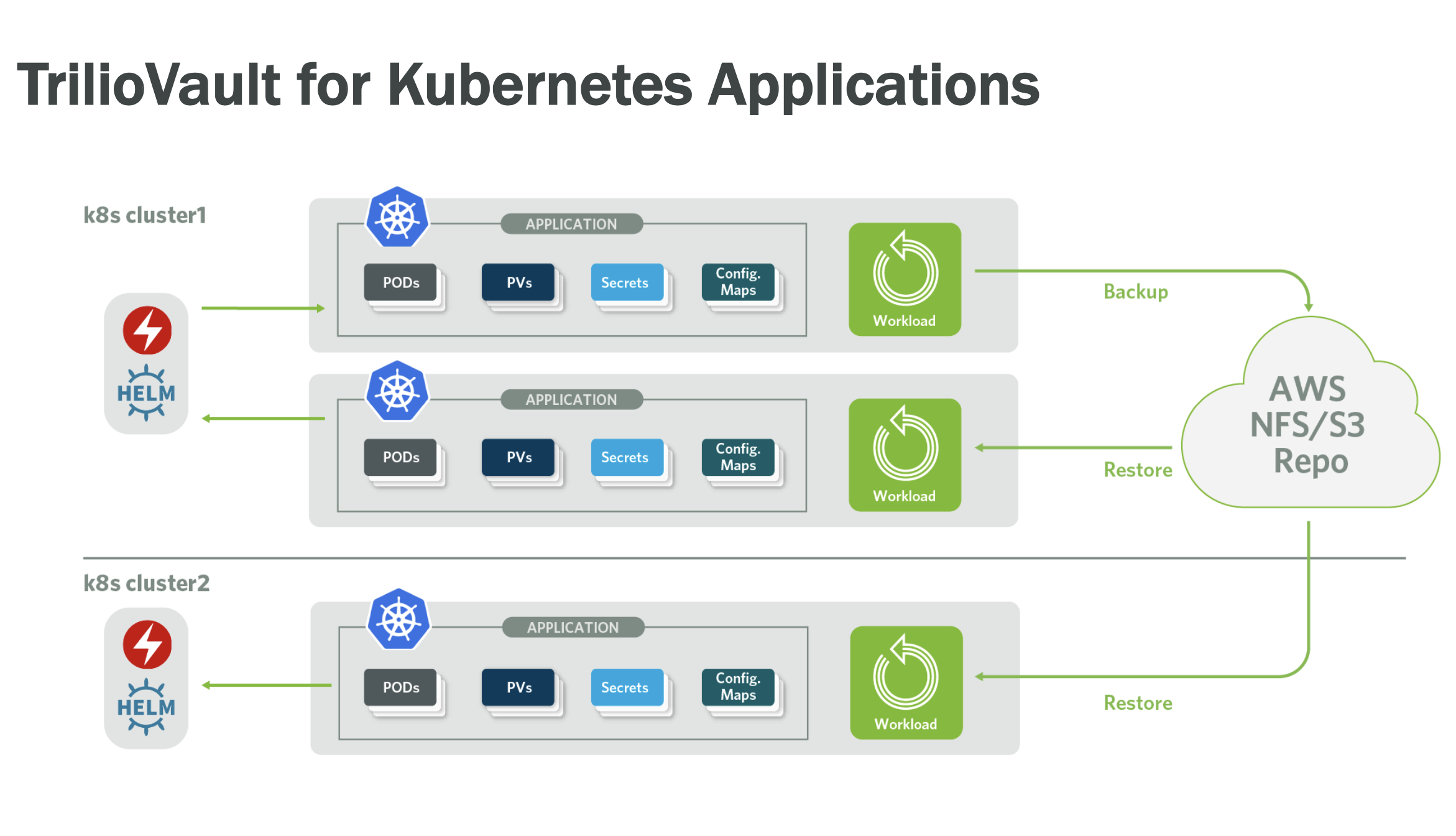
Safaii says that as more stateful applications are deployed on Kubernetes clusters, IT organizations are wrestling with data protection issues reminiscent of the transition to virtual machines two decades ago. Many IT organizations are finding their legacy backup tools for virtual machines can’t be applied to containerized application environments. Via an agentless architecture, however, Trilio enables IT organizations to use the same data protection platform across both containers and virtual machines, says Safaii.
It’s still early days as far as data protection for Kubernetes is concerned. Still, the battle is already becoming fierce as incumbent providers of data protection platforms look to challenge rival startup companies that only support Kubernetes. What makes the transition to Kubernetes especially challenging for incumbent vendors is not just the ephemeral nature of containers but also the fact that DevOps teams typically want to be able to access an API to include any platform within their toolchain.
Of course, it won’t be known who and when will be backing up containerized applications running on Kubernetes clusters. However, there is general agreement backups will need to be done a lot more often than on legacy platforms.