MapR Embraces Kubernetes for Big Data
MapR Technologies announced it has integrated its distribution of the open source Apache Spark framework and the Drill query engine platform with Kubernetes.
Suzy Visvanathan, senior director for product management at MapR, says these integration efforts will make it significantly easier for IT organizations to make available compute and storage resources available independently and dynamically as workload requirements scale up and down.
Just as important, it also means that much of the complexity associated with managing Kubernetes clusters can be reduced by relying on the application programming interfaces (APIs) that MapR has invoked to manage such clusters at a high level of abstraction, adds Visvanathan.
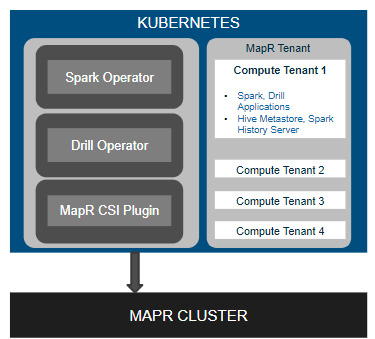
To achieve that goal, MapR has developed a Tenant Operator that creates Kubernetes namespaces that end users can designate to run Spark, Drill, Hive Metastore, Tenant CLI and the Spark History Server. Each tenant can then access its own set of storage resources. A separate Spark Job Operator tool can be employed to deploy multiple Spark instances in different pods. Drill Operator, meanwhile, allows end users to launch individual Drillbit that automatically scales queries on as required.
Finally, MapR has made available a plugin to mount persistent volumes to run stateful applications in Kubernetes. That plugin is based on the Container Storage Interface (CSI) developed under the auspices of the Cloud Native Computing Foundation (CNCF). MapR announced support for CSI earlier this year.




 Apache Spark has gained popularity as a framework for processing data that is stored in a Hadoop cluster in memory. By deploying its distribution of Apache Spark and Drill on Kubernetes, MapR makes it possible to dynamically invoke pods within a Kubernetes to scale Spark and Drill processes as needed, says Visvanathan.
Apache Spark has gained popularity as a framework for processing data that is stored in a Hadoop cluster in memory. By deploying its distribution of Apache Spark and Drill on Kubernetes, MapR makes it possible to dynamically invoke pods within a Kubernetes to scale Spark and Drill processes as needed, says Visvanathan.
The approach MapR is pursuing with Kubernetes not only provides a way to more efficiently employ IT infrastructure in support of Big Data applications, but it also reduces the need for IT organizations to develop skill sets that are specific to Kubernetes. The teams that have overseen the development of Kubernetes continue to publish northbound application programming interfaces (APIs) that increasingly make it possible to embed Kubernetes as a foundational layer within another product or service offering. As that approach to embedding Kubernetes within other offerings continues to evolve, many organizations may find that, thanks to various automation frameworks, they are adopting Kubernetes without having set it up on their own.
Of course, once IT organizations are exposed to Kubernetes via these offerings, the expectation is many of them will rapidly become more comfortable deploying Kubernetes clusters on their own. In the meantime, as various classes of middleware such as databases and frameworks such as Spark are deployed on Kubernetes, organizations may need to decide who in their organization should manage what infrastructure. After all, if, for example, Kubernetes becomes an enabling technology that is primarily embedded within a larger platform, the need for dedicated IT personnel to manage those clusters could be reduced greatly.