Kubernetes Best Practices in Production
No doubt, DevOps has come a long way. Platforms such as Docker and Kubernetes have helped companies ship their software faster than ever. With the ever-growing usage of containers to build and ship software, Kubernetes has gained colossal popularity among software enterprises as a de facto container orchestration tool.
Kubernetes has excellent features that support scaling, zero-downtime deployments, service discovery, automatic rollout and rollback capabilities, to name a few. To manage your container deployment at scale, Kubernetes is a must, as it enables the flexible distribution of resources and workloads. Kubernetes in production is a great solution, but it takes some time to set up and become familiar with it. Since many companies want to use Kubernetes in production these days, it is essential to prioritize some best practices. In this article, we will look at some Kubernetes best practices in production.
Kubernetes in Production
Kubernetes has a complex and steep learning curve, because it is loaded with feature-rich capabilities. Production operations should be handled with utmost care and priority. If you don’t have the in-house talent, you can always outsource this to Kubernetes-as-a-service (KaaS) providers to take care of the best practices for you. But suppose you are managing Kubernetes in production by all yourself—in that case, it is important to understand and implement these best practices especially around observability, logging, cluster monitoring and security configurations.
As many of us know, running containers in production is not easy, requiring among other things a lot of effort and computing resources. There are many orchestration platforms on the market, but Kubernetes has gained much traction and support from the major cloud providers.
Kubernetes, containerization and microservices bring benefits but they also introduce security challenges. Kubernetes pods can be quickly spun up across all infrastructure classes, leading to a lot more internal traffic between pods; hence, they pose a security concern. Also, the attack surface for Kubernetes is usually larger. You must also consider that the highly dynamic and ephemeral environment of Kubernetes does not blend well with legacy security tools. In general, Kubernetes is hard.



Gartner predicts that by 2022, more than 75% of global organizations will be running containerized applications in production, up from less than 30% today. By 2025, more than 85% of global organizations will be driving containerized applications in production, which is a significant increase from fewer than 35% in 2019. Cloud-native applications require a high degree of infrastructure automation, DevOps and specialized operations skills, which are tough to find in enterprise IT organizations.
Developing a Kubernetes strategy that applies best practices across security, monitoring, networking, governance, storage, container lifecycle management and platform selection is a must.
There are several aspects that should be considered with Kubernetes.
Perform Health Checks With Readiness and Liveness Probes
It can be complicated to manage large and distributed systems, particularly when something goes wrong. To make sure app instances are working, it is crucial to set up Kubernetes health checks.
Creating custom health checks allows you to tailor them to your environment and needs.

Readiness
Readiness probes are intended to let Kubernetes know if the app is ready to serve the traffic. Kubernetes will always make sure the readiness probe passes before allowing a service to send traffic to the pod.
Liveness
How can you know if your app is still alive or dead? Liveness probes help. If your app is dead, Kubernetes removes the old pod and replaces it with a new one.
Resource Management
It is a good practice to specify resource requests and limits for individual containers. Another good practice is to divide Kubernetes environments into separate namespaces for different teams, departments, applications and clients.
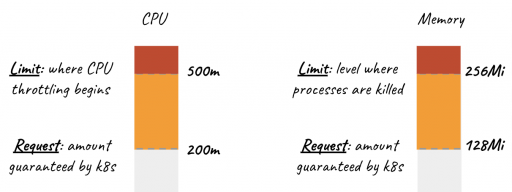
Kubernetes Resource Usage
Kubernetes resource usage looks at the amount of resources that are utilized by a container/pod Kubernetes environment in production. Hence, it is very important to keep an eye on the resource usage of pods and containers—more usage translates to more cost.
Resource Utilization
Ops teams usually want to optimize and maximize the percentage of resources consumed by pods. Resource usage is one such indicator of how optimized your Kubernetes environment actually is. You can consider that an optimized Kubernetes environment is one in which the average CPU usage of the containers running is optimal.
Enable RBAC
Role-based access control (RBAC) is an approach used to restrict access and admittance to users and applications on the system or network.
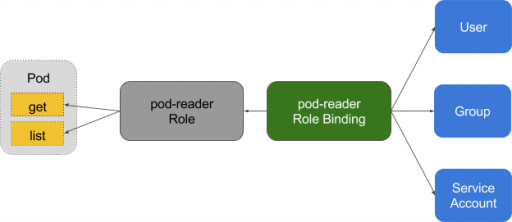
RBAC was introduced in the Kubernetes 1.8 version, which uses rbac.authorization.k8s.io API group to create authorization policies.
RBAC is used for authorization in Kubernetes to enable access to user, account, add/remove permissions, set up rules and much more. It essentially adds an extra security layer to a Kubernetes cluster. RBAC restricts who can access your production environment and the cluster.
Cluster Provisioning and Load Balancing
Production-grade Kubernetes infrastructure usually needs to have certain critical aspects such as high availability, multi-master, multi-etcd Kubernetes clusters, etc. The provisioning of such clusters typically involves tools such as Terraform or Ansible.
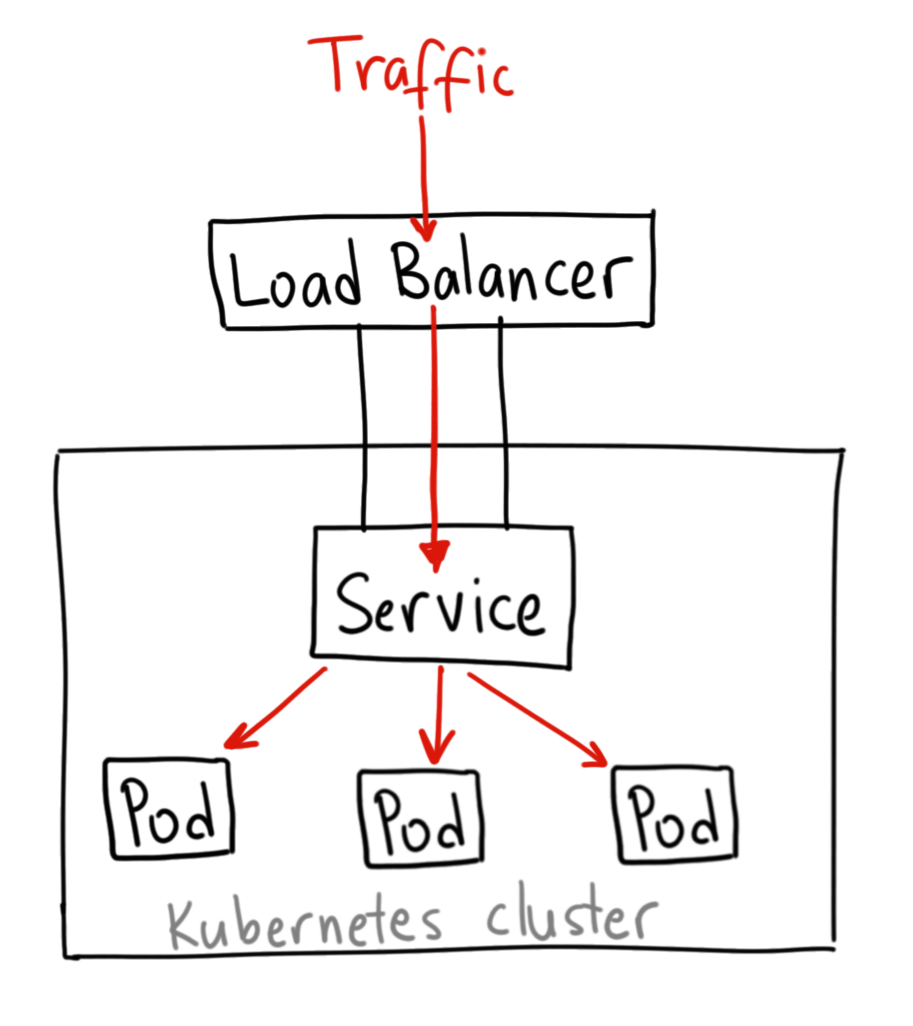
Once clusters are all set up and pods are created for running applications, the pods are equipped with load balancers, which route traffic to the service. Load balancers are not default with the open source Kubernetes project; hence, integration with tools tools that extend the Kubernetes ingress controller to provide the load-balancing capability.
Attach Labels to Kubernetes Objects
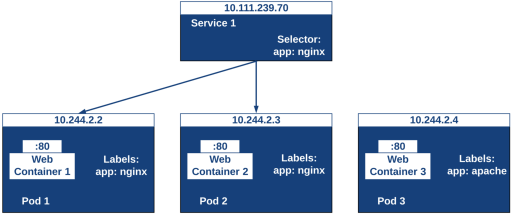
Labels are like key/value pairs attached to objects, such as pods. They are meant to be used as identifying attributes of objects that are important and meaningful to users. When using Kubernetes in production, one important thing you can’t neglect is labels, as they allow Kubernetes objects to be queried and operated in bulk. The specialty of labels is that they can also be used to identify and organize Kubernetes objects into groups. One of the best use cases of this is grouping pods based on the application they belong to. Here, teams can build and have any number of labeling conventions.
Set Network Policies
Setting network policies is crucial when it comes to using Kubernetes.

Network policies are nothing but objects that enable you to explicitly state and decide what traffic is permitted and what’s not. This way, Kubernetes will be able to block all other unwanted and non-conforming traffic. Defining and limiting network traffic in clusters is one of the basic and necessary security measures and is highly recommended.
Each network policy in Kubernetes defines a list of authorized connections as stated above. Whenever any network policy is created, all the pods that it refers to are qualified to make or accept the connections listed. In simple words, a network policy is basically a whitelist of authorized and allowed connections only—a connection, whether it is ‘to’ or ‘from’ a pod, is permitted only if it is sanctioned by at least one of the network policies that apply to the pod.
Cluster Monitoring and Logging
Monitoring deployment is critical while working with Kubernetes. It is vital to ensure the configurations, performance and traffic remain secure. Without logging and monitoring, it is impossible to diagnose issues that happen. To ensure compliance, monitoring and logging become essential.
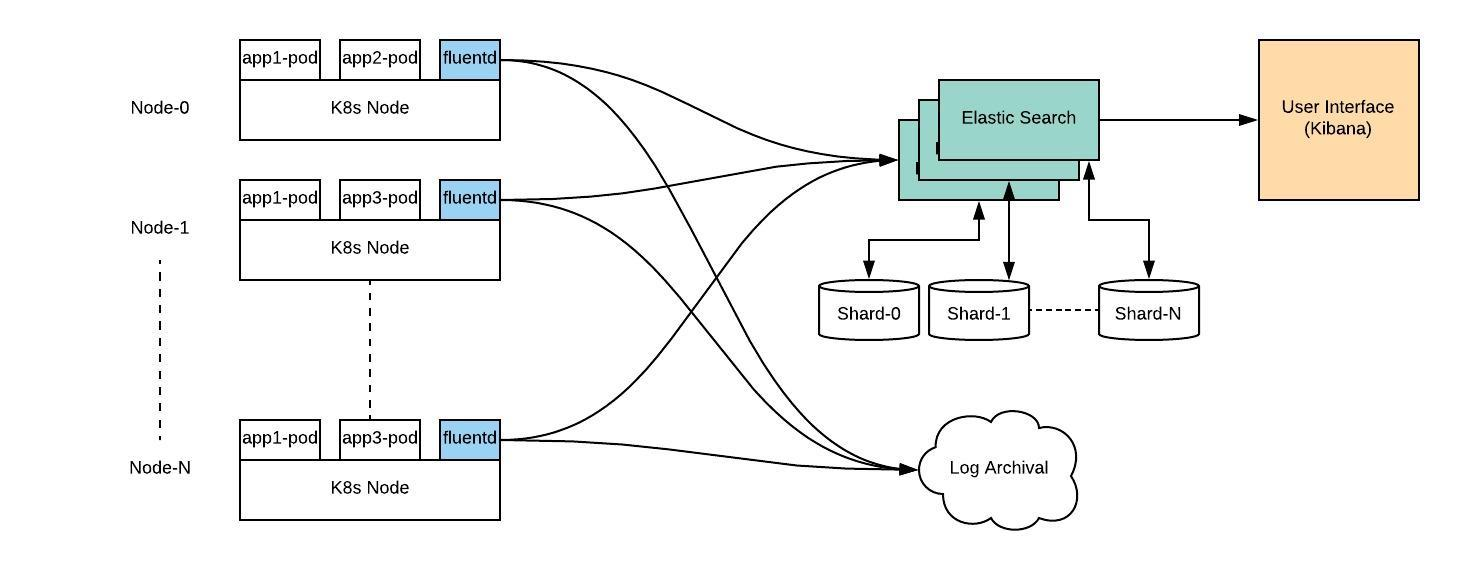
When it comes to monitoring, it is necessary to set up the logging capabilities on every layer of the architecture. The logs generated will help to enable security tooling, audit functionality and analyze performance.
Start With Stateless Applications
Running stateless apps is significantly easier than running stateful apps, but this thinking is changing with the increasing adoption of Kubernetes Operators. In fact, for teams new to Kubernetes, it is recommended to begin with stateless applications.
A stateless backend is advised so that the development teams can make sure that there are no long-running connections that make it more challenging to scale. With stateless, developers can also deploy applications more efficiently with zero downtime.
Stateless applications are believed to make it easy to migrate and scale as and when required according to business needs.
Enable the Use of Auto Scalers
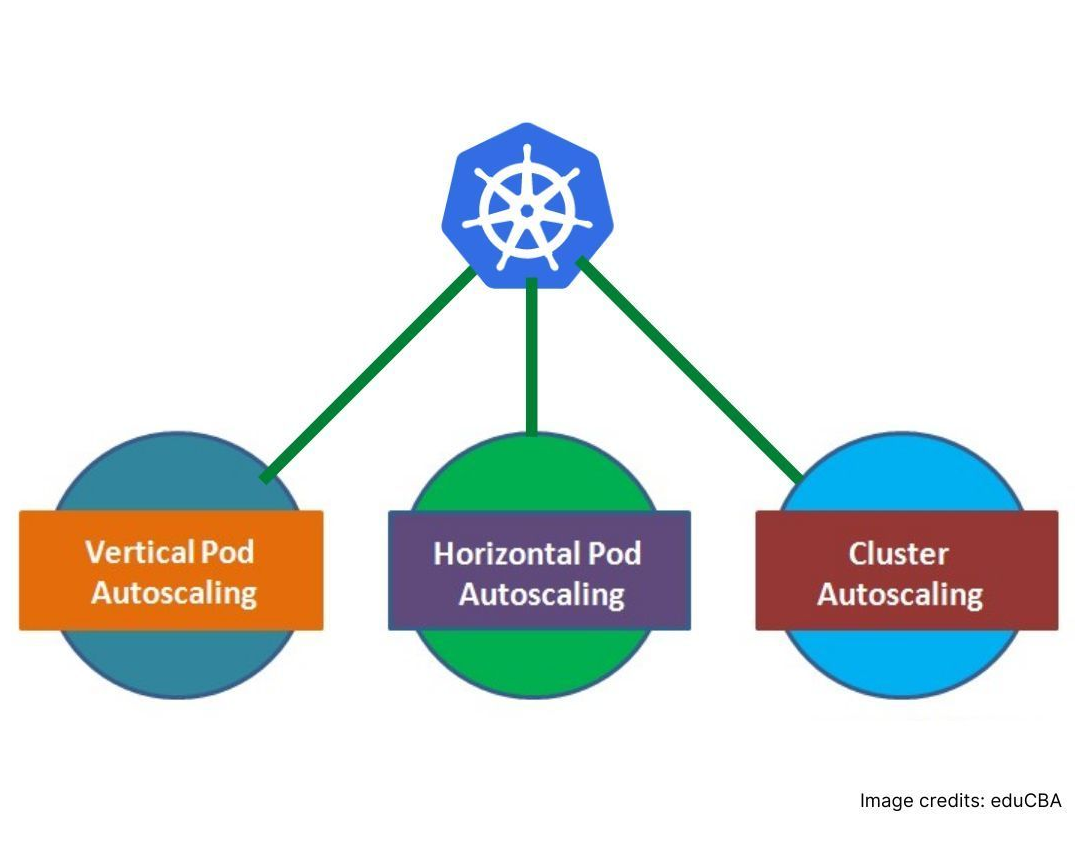
Kubernetes has three auto-scaling abilities for deployments: horizontal pod autoscaler (HPA), vertical pod autoscaler (VPA) and cluster autoscaling.
Horizontal pod autoscaler automatically scales the quantity of pods in deployment, a replication controller, replica set or stateful set based on perceived CPU utilization.
Vertical pod autoscaling recommends suitable values to be set for CPU and memory requests and limits, and it can automatically update the values.
Cluster Autoscaler expands and shrinks the size of the pool of worker nodes. It adjusts the size of a Kubernetes cluster depending on the current utilization.
Control the Sources of Runtimes
Have control of the source from where all containers are running in the cluster. If you allow your pods to pull images from public sources, you don’t know what’s really running in them.
If you pull them from a trusted registry, you can apply policies on the registry to allow pulling only safe and certified images.
Continuous Learning
Keep evaluating the state of your applications and setup to learn and improve. For example, by reviewing a container’s historical memory usage you can determine you can allocate less memory to save costs.
Protect Your Important Services
Using Pod priority you can set the importance of different services running. For example, you can prioritize RabbitMQ pods over application pods for better stability. Or, you can make your Ingress Controller pods more important than data processing pods to keep services available to users.
Zero Downtime
Support zero downtime upgrades of the cluster and of your services by running them all in HA. This will also guarantee higher availability for your customers.
Use pod anti affinity to make sure multiple replicas of a pod are scheduled on different nodes to ensure service availability through planned and unplanned outages of cluster nodes.
Use pod disruption budgets to make sure you have the minimal number of replicas up at all cost.
Plan to fail
“Hardware eventually fails. Software eventually works.” (Michael Hartung)
Conclusion
As we all know, Kubernetes is the de facto orchestration platform in DevOps. Kubernetes environments must work in production from an availability, scalability, security, resilience, resource management and monitoring perspective. Since many companies are using Kubernetes in production, it becomes imperative to follow these above mentioned Kubernetes best practices to smoothly and reliably scale your applications.