HPE Extends Data Fabric Across Multiple Kubernetes Clusters
Hewlett Packard Enterprise (HPE) has extended the capabilities of a rechristened container platform to now include support for a data fabric spanning multiple Kubernetes clusters that can be physically located in data centers in different geographies.
Now known as the HPE Ezmeral, the data fabric is based on technology it gained from HPE’s acquisition of MapR Technologies last year. The data fabric creates a global namespace that is accessible via application programming interfaces (APIs). Containerized and non-containerized applications can access and store data as files, tables or event streams. A data mirroring capability makes it possible to move data within or between clusters using bi-directional, multi-master tables or event stream replication.
Nanda Vijaydev, a distinguished technologist and lead data scientist for HPE, says HPE Ezmeral Data Fabric 6.2 will make it possible for IT organizations to set up fleets of Kubernetes clusters across distributed across multiple geographic locations.
The latest release of the data fabric also adds support for a snapshot restore capability; fine-grained placement of data on heterogeneous nodes that can be applied to different classes of storage devices; policy-based security for better data governance; and last access tracking.
In addition, this release adds flash storage and global file check enhancements, improved erasure coding performance and rebuild, better management metrics and support for external key management.




Vijaydev says HPE Ezmeral platform is designed to enable IT organizations to deploy a stackable set of services on top of a core Kubernetes cluster as their container application environment evolves and matures. The HPE Ezmeral Data Fabric makes it possible to manage data at a very granular level across a fleet of Kubernetes clusters, she notes.
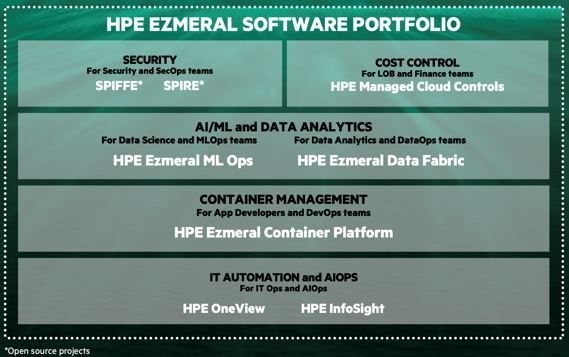
As more organizations build advanced containerized applications incorporating things such as machine learning algorithms that require massive amounts of data, HPE is betting IT organizations will require what amounts to a new stack of software to address both machine learning operations (MLOps) and the management of Kubernetes clusters.
HPE will make available those capabilities either on a platform that an internal IT team manages or a Greenlake platform through which it manages not only the IT infrastructure but also updates to select third-party packaged application environments if required.
It’s unclear to what degree internal IT organizations will want to manage IT infrastructure as container application environments become more complex. HPE is betting more organizations over time will prefer to focus their efforts on data science and application development.
In the meantime, advanced applications that make use of machine learning algorithms have emerged as a primary driver for adopting Kubernetes clusters. Building and training machine learning models become more feasible when containers are employed to create a modular framework that makes it easier to update what would otherwise be massive monolithic applications. It’s not clear to what degree those applications will be built and deployed on-premises or in the cloud, but it’s clear HPE is certain organizations will be deploying more than a few of them on Kubernetes clusters in multiple local data centers at significant scale.