A Maturity Model for Cloud-Native Databases
Companies have been leveraging Kubernetes and other technologies to move workloads to the clouds. But several nagging challenges have remained: what to do with the data layer, what technologies should you use, where should an organization keep data and how should you move it? At the center of these questions is the database.
Many of the databases that support our apps have been around for a long time—well before the notion of “cloud-native” took hold. Today, there’s a laundry list of characteristics that make a database a suitable data storage option for modern, scalable applications, including scalability, elasticity, resiliency, observability and automation (we explored these in a recent post,
“The Search for a Cloud Native Database“).
But what does a modern, cloud-native data architecture really look like? In this article, we’ll walk you through a maturity model for cloud-native databases to assess data layer technology as part of an overall cloud architecture and to ensure that a consistent level of maturity is applied across the stack.
Cloud Usage Patterns
Let’s start by considering some of the traditional patterns that describe cloud services and their usage. Both providers and consumers of cloud services have found it useful to speak in terms of various levels of capability exposed “as-a-service” via APIs. The initial set of patterns included infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS) and software-as-a-service (SaaS).





More recently, other variants of the PaaS pattern have emerged, including container-as-a-service (CaaS) and function-as-a-service (FaaS). Let’s try to make sense of these patterns and where they can be applied in our cloud architectures.
A good way to examine these patterns in more detail is by comparing them side-by-side, at each layer from the network up through the application. Items shown in gold are the cloud provider’s responsibility, while the items in blue are the responsibility of the consumer:
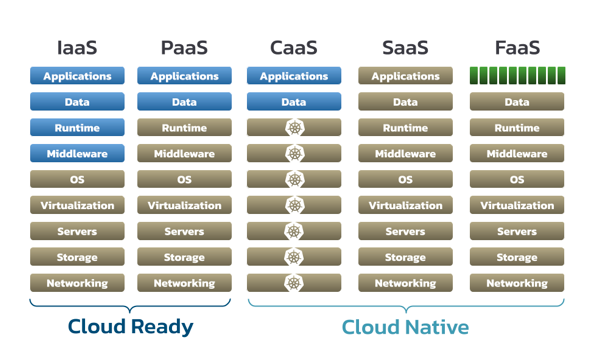
There’s a lot going on in this picture, so let’s unpack some of the details:
- With IaaS, the cloud provider only provisions your servers—you still have to provision user accounts and install all of the components and middleware that your application needs.
- With PaaS, there is less work for consumers—you can deploy your component in existing runtimes, such as application servers.
- With SaaS, also known as managed services, you are using software through APIs that provide business capabilities at a higher level of abstraction.
Two variants of the PaaS pattern have emerged that are important for the context of cloud-native application development:
- CaaS is a flavor of PaaS where the runtime is a container orchestrator such as Kubernetes.
- FaaS, which is sometimes also referred to as “serverless,” is an even more abstracted version of PaaS in which you deploy snippets of code that are invoked behind an endpoint
Note that these patterns can be combined. Your cloud ecosystem might include a mix of virtual machines (VMs) deployed on an IaaS, multiple microservices deployed in containers on a CaaS, third-party SaaS for commodity capabilities you don’t want to implement yourself, functions deployed to a FaaS to help coordinate workflows and data flows between other services, and so on.
The Cloud-Native Database Maturity Model
With these cloud architecture patterns as background, let’s turn our focus toward defining a maturity model for cloud-native databases and data services, using the definition of cloud-native proposed by Bill Wilder in his 2012 book, Cloud Architecture Patterns: “Any application that was architected to take full advantage of cloud platforms.”
Examining the cloud usage patterns in terms of this definition, IaaS and PaaS are what we might term “cloud-ready,” because you can install any application you wish ad hoc, as is, without adaptation. However, this comes at the cost of the flexibility offered by true cloud-native solutions. Only CaaS, SaaS and FaaS can truly be considered cloud-native in the sense of being architected for the cloud, and can therefore be considered to represent different maturity levels of cloud-native architecture:

In this model, we’ll represent CaaS as ‘Kubernetes native,’ SaaS as ‘managed services,’ and FaaS as ‘serverless.’ If we include a ‘cloud-ready’ maturity level to represent IaaS / PaaS as a baseline, we get a maturity model that looks like this:

Let’s examine these maturity levels one at a time from least mature to most mature.
Maturity Level 0: Cloud-Ready Data
The first maturity level is easy to achieve; it’s the classic lift and shift paradigm. Any system that can be deployed on IaaS would be considered cloud-ready. A pattern we’ve often observed is the monolithic application deployed in a VM, with an embedded database included. As long as you can package your application in a VM (or several VMs) and plumb any required networking, you can run it in the cloud. This is a perfectly valid deployment option and is often an important transitional step in an organization’s adoption of cloud, but can’t legitimately be considered cloud-native. We’re aiming our sights a bit higher, so let’s proceed to the next level.
Maturity Level 1: Kubernetes-Native Data
This level typically represents a state where you’ve broken monolithic applications into smaller microservices which can be deployed in containers and scaled independently. This is an important step, but a container technology like Docker alone cannot provide everything that is needed for managing application life cycles and ensuring high availability and scalability.
The Docker runtime and Docker-compose are quite suitable for development and test environments, but for production usage, you need to monitor what’s happening and act to maintain your level of service. Container orchestrators such as Kubernetes were created for this exact purpose.
The rapid adoption of Kubernetes is well known. A 2020 Cloud Native Computing Foundation (CNCF) survey found that 92% of responding companies run containers in production, and 83% of those deployments use Kubernetes.
Given the popularity of Kubernetes for deploying microservices and applications, why don’t we see more databases deployed there? While Kubernetes was originally designed for stateless workloads, a lot of progress has been made through the introduction of stateful sets and persistent volumes (Cassandra is a database that embodies cloud-native principles and can be deployed effectively to containers).
However, because databases have taken longer to mature on Kubernetes, we have frequently observed architectures in which containerized applications delegate storage responsibilities to components running outside Kubernetes. One example of this would be self-managed databases running in VMs or on bare metal. This approach leads to increased complexity in networking and security, as well as duplication of capabilities such as monitoring. A more cloud-native approach to delegating storage responsibility is to use a managed database service such as those available from third-party providers. That brings us to the next maturity level.
Maturity Level 2: Managed Data Services
Simply deploying a database in a containerized environment such as Kubernetes is, by itself, not enough to deliver the cloud-native database characteristics described above (scalability, elasticity, resiliency, observability and automation). To reach the level of a managed service, or “database-as-a-service” (DBaaS), you need additional operational logic for things such as:
- Maintenance operations including scaling up/down, backup/restore, software updates and troubleshooting
- Monitoring and observability including metrics, logging and tracing
For example, cass-operator is an open source Kubernetes operator for Cassandra that handles maintenance tasks like those described above. K8ssandra is another open source project that builds on cass-operator to provide a complete ecosystem for deploying and running Cassandra on Kubernetes. This approach gives you the flexibility to create your own tailored deployment of well-managed OSS components that approximates the functionality of a third-party DBaaS.
However, to provide a mature SaaS solution in the data space, you need “data-as-a-service,” not just “database-as-a-service.” More than just an endpoint that supports a database query language like CQL or SQL, developers crave APIs that they can easily access with familiar languages and frameworks. This is the motivation behind another open source project – a data gateway called Stargate. Stargate provides a RESTful API supporting the familiar HTTP access patterns developers are accustomed to, a new GraphQL API that’s especially useful for web and mobile apps and schemaless document-oriented APIs.
Maturity Level 3: Serverless Data
Even when you have a managed service that you are managing yourself or consuming from a third party, there are still cost challenges to consider. The classic problem with both of these cases is this: how can you tune the amount of resources you deploy to the actual needs of your workload in order to minimize waste? Even in a highly scalable, elastic system like Cassandra, it can be difficult to scale computing and storage resources independently. What if you were able to scale only the part of the database that you need?
This is where a FaaS or serverless approach comes in. By factoring a cloud-native database such as Cassandra into smaller functions, the compute and storage utilization can be decoupled and managed more efficiently. The interfaces, routers, reads and writes become separate functions that can scale independently. This model also promotes elastic resource utilization as you “scale to zero,” and supports multi-tenancy.

This architectural approach changes the conversation from “Can my database run in Kubernetes?” to “How can I get the lowest-cost solution for my specific database workload?”
As the practice of cloud computing continues to mature, it’s important that we apply cloud-native architecture principles to all layers of our stacks. We believe a maturity model for cloud-native databases based on best practices like containerization (CaaS), managed services (SaaS) and serverless (FaaS) represents a helpful maturation path for data in the cloud. Open source projects like K8ssandra and Stargate provide a great opportunity for industry collaboration to make great strides forward in maturing the data layer. We’d love to hear your feedback on this maturity model and the technologies introduced here.
Cedrick Lunven, director of developer advocacy at DataStax, co-authored this piece.