Pure Storage Adds DBaaS for Kubernetes Storage
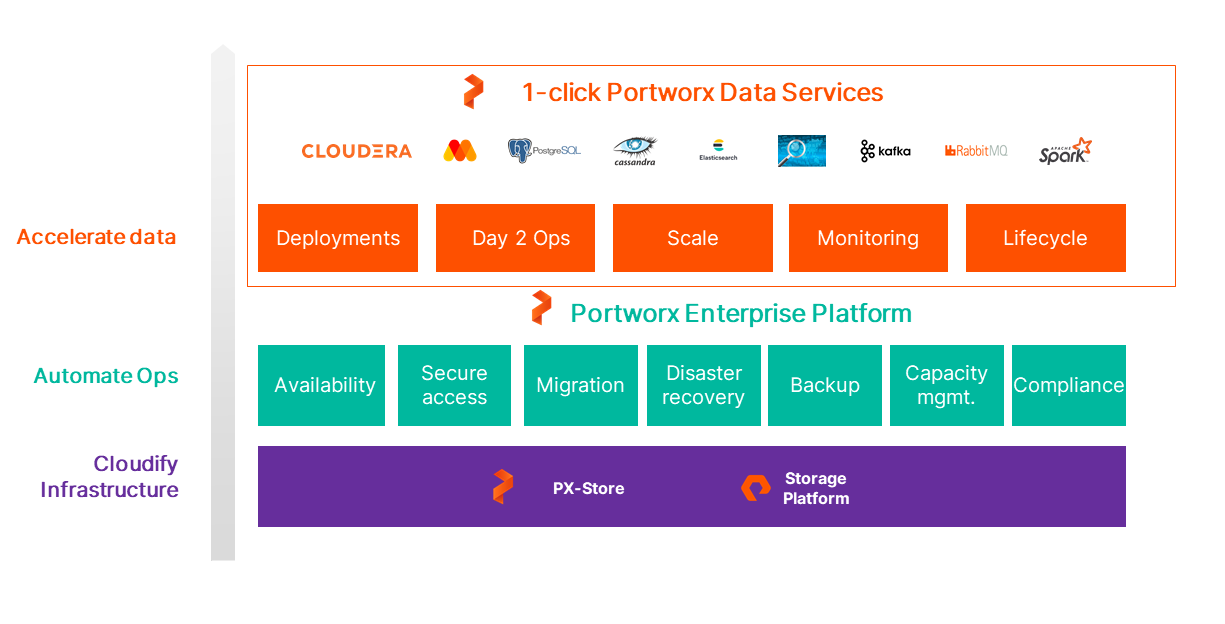
Pure Storage unveiled a database-as-a-service (DBaaS)platform for Kubernetes environments, dubbed Portworx Data Services, that is designed to make it possible to provision a database with a single click.
At the same time, Pure Storage launched Pure Fusion, an autonomous storage-as-code platform that enables IT teams to logically aggregate pools of FlashArray//X, FlashArray//C and Pure Cloud Block Storage with future support for FlashBlade and Portworx storage software for Kubernetes clusters. Pure Storage acquired Portworx last year.
Finally, Pure Storage has also updated Pure1, the cloud-based management platform infused with artificial intelligence (AI) that it provides to manage storage systems. IT teams can now view in real-time the degree to which service level agreements (SLAs) are being met in addition to visualizing container storage platforms running Portworx software.
Ajay Singh, chief product officer for Portworx, says Portworx Data Services provides IT teams running Kubernetes clusters with access to a wide range of SQL and NoSQL databases as well as search and streaming data platforms that can be automatically deployed and continuously updated. It includes monitoring, backups, high-availability, disaster recovery, migration, auto-scaling and security that are all delivered using an operating model that is similar to any cloud-based service, adds Singh.
Portworx Data Services and Pure Fusion are the latest examples of how automated storage and database management is becoming, notes Singh. Most organizations will soon be able to take advantage of levels of automation that previously would have required them to hire a site reliability engineer (SRE) to create custom code, says Singh.




It’s unclear what impact that level of automation will have on the need for storage administrators. Most of them are evolving their skills as it becomes clearer that data needs to be managed in isolation from the applications that created it and the infrastructure required to store it. However, the management of the underlying databases and storage infrastructure is becoming increasingly automated.
Of course, it’s still early days in terms of deploying stateful applications in Kubernetes environments that require access to persistent forms of storage. However, as more IT teams decide to deploy these types of applications across fleets of Kubernetes clusters the more need there is for automation. Most organizations cannot afford to hire large numbers of administrators to manage fleets of Kubernetes clusters.
Taking advantage of that automation, however, usually requires IT teams to fund an upgrade to their existing storage systems. Pure Storage is betting the cost of any such upgrade will be overshadowed by a reduction in the total cost of storage management at a time when the amount of data being stored continues to exponentially grow.
At this point it’s only a matter of time before most organizations are, at the very least, considering storage platforms for Kubernetes environments. Not every cloud-native application will always be stateless or rely on an external storage system to eventually store data. The challenge now is determining just how simple those storage platforms will be to manage as the Kubernetes environment continues to scale out.