NetApp Automates Apache Spark Management on Kubernetes
NetApp today announced Spot Wave by NetApp, an offering that automates the deployment of the open source Apache Spark in-memory computing framework on Kubernetes clusters. Spot Wave enables Apache Spark deployment on Kubernetes in 30 seconds, without requiring any intervention on the part of an internal IT team.
At the same time, NetApp Spot Ocean serverless compute engine for deploying containers is now available on the Microsoft Azure Kubernetes Service. That tool is already available on the Elastic Container Service (ECS) and Elastic Kubernetes Service (EKS) from Amazon Web Services, as well as Google Kubernetes Engine (GKE). That approach gives IT teams a common framework for managing the deployment of containers across multiple clouds, versus having to invoke a separate similar capability on each cloud platform.
Spot Wave, which is based on Spot Ocean, makes it possible for data scientists to spin up an Apache Spark cluster using a serverless compute engine accessible via a graphical user interface (GUI). In addition to provisioning the cluster, Spot Wave automatically sizes it while leveraging Kubernetes and machine learning algorithms to automatically scale workloads up and down, as needed, to employ compute resources more efficiently. In addition, Spot Wave determines whether to employ spot, on-demand or reserve instances to optimize costs. It also will continuously tune Spark configuration for jobs based on analysis of job requirements.
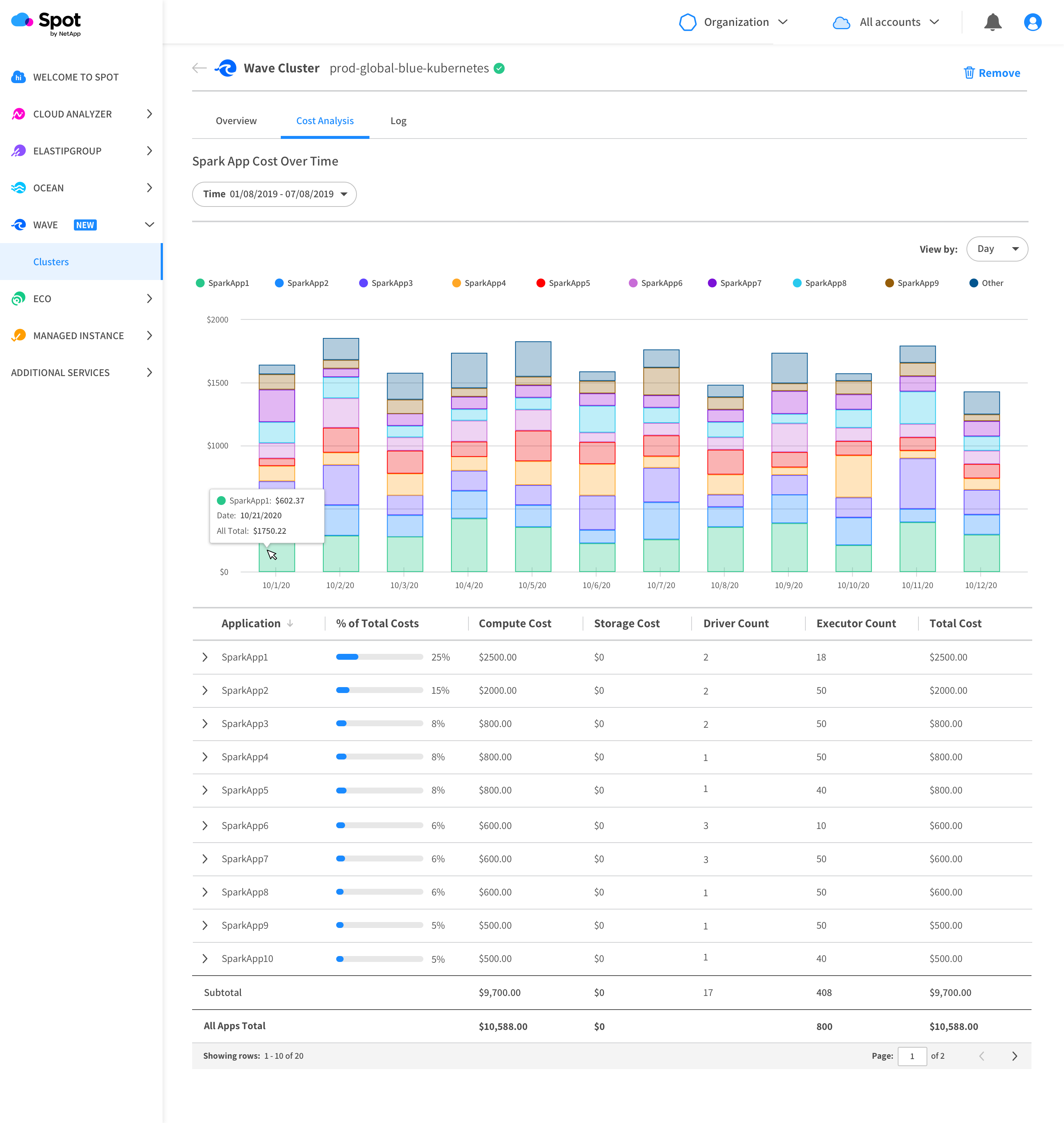
Amiram Shachar, vice president and general manager for Spot by NetApp, says Spot Ocean was developed as an alternative to the AWS Fargate service. Spot Wave extends that capability in a way that enables an Apache Spark cluster to be spun up in less than half a minute, Shachar says. Spot Wave provides that capability by, in part, programmatically employing Kubernetes as an alternative to YARN to manage Apache Spark clusters, Shachar adds.



In general, Shachar says adoption of the core Spot Ocean serverless compute engine service has increased 450% in the last year, as the management of container environments in the cloud becomes more automated. Naturally, that level of automation has significant implications for internal IT operations teams. It’s only a matter of time before NetApp and others further extend this capability to automate the provisioning of a wider range of databases. NetApp has already launched a complementary managed service for automating data management across fleets of Kubernetes clusters.
Ultimately, the goal is to enable organizations to devote more of their limited resources to application development and building data science teams by breaking the current, fundamentally broken cycle of manually provisioning and tuning clusters, says Shachar. At the same time, the amount of IT infrastructure that an organization could effectively consume should increase, as management tasks become more automated.
Kubernetes, of course, is designed to be a platform on which other platforms are built. It may not be clear to many IT operations teams just how automated the management of IT can become on top of Kubernetes. The days when IT operations teams needed to babysit fleets of clusters may be soon come to an end. The focus, now, will be on how to manage all the application code deployed on those clusters that increases by the day.