Kasten by Veeam Extends Reach of K8s Data Protection Platform
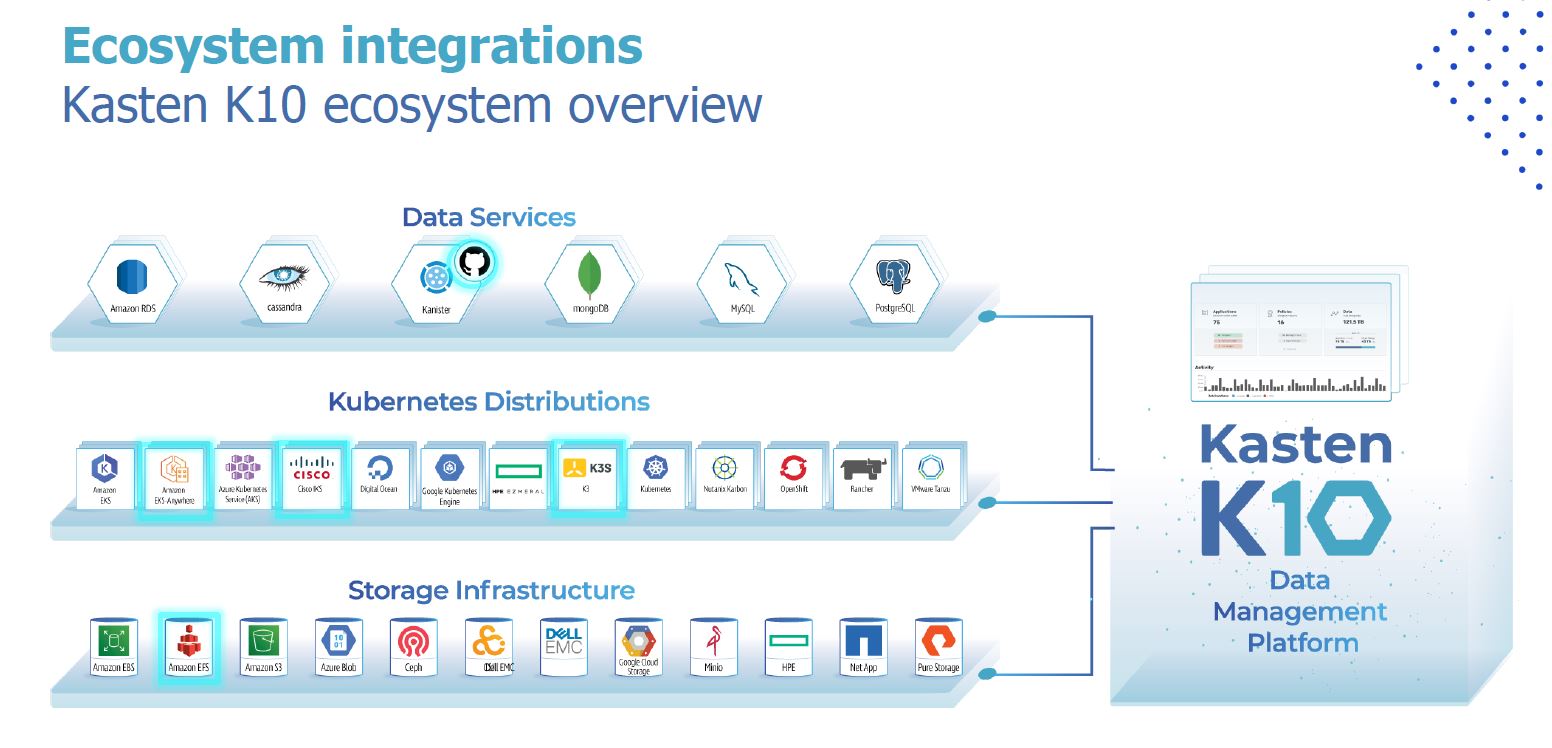
Kasten by Veeam today updated its Kasten K10 data management platform for Kubernetes environments to make it simpler to deploy. In addition, Kasten K10 can protect computing platforms running the lighter-weight K3s distribution of Kubernetes and those that are managed via the Elastic Kubernetes Service (EKS) Anywhere distribution of Kubernetes.
At the same time, version 4.5 of Kasten K10 has added support for Kafka, Apache Cassandra, K8ssandra and the Amazon Relational Database Service (RDS) running on Kubernetes clusters.
Finally, the latest version of Kasten K10 provides integration with Veeam Backup & Replication storage repositories, which makes it possible to now back up data to platforms such as Cisco S3260 and HPE Apollo servers, ReFS- and XFS- formatted block storage, deduplication appliances as well as platforms that support the server message block (SMB) protocol. Kasten by Veeam became an arm of Veeam following its acquisition last year.
Gaurav Rishi, vice president of product for Kasten by Veeam, says as more stateful applications are deployed across fleets of Kubernetes clusters the need to protect data in that environment is becoming a higher IT priority.
As part of an effort to make it simpler to achieve that goal, Rishi says the integrations included in the core platform reduce the time it takes to deploy Kasten K10.




Rishi says it’s unlikely most organizations will be standardizing on a single distribution of Kubernetes anytime soon, which is why organizations will require a data protection platform that can support instances of Kubernetes deployed in the cloud, on-premises IT environments or at the network edge. Most organizations will not want a backup and recovery tool that is only applicable to single platform because one of the primary reasons they shifted to Kubernetes was to avoid being locked into a single vendor, adds Rishi.
At the same time, Rishi notes that the line between backup and recovery and disaster recovery continues to blur. IT teams that deploy modern cloud-native applications are looking for integrated platforms capable of not only backing up data but also rehydrating application environments as quickly as possible in the event a cluster suddenly goes offline.
It’s still early days as far as edge computing platforms are concerned, but they are likely to soon force the stateful application issue. Most of the applications deployed on Kubernetes clusters are stateless in the sense that they rely on external platforms to store and access data. Edge computing platforms, however, are being employed to process and analyze data at the point where it is being created and consumed as part of a larger effort to drive digital processes that operate in near-real-time. Many of those edge computing platforms will be running distributions of Kubernetes that contain data that will need to be backed up. In fact, many of those edge computing platforms will be primary targets for ransomware attacks. Having access to pristine data is the only way to effectively thwart those attacks.
Data protection is one of those routine IT processes that tend to get overlooked as organizations roll out new platforms. There is already no shortage of options when it comes backup and recovery in Kubernetes environments. The biggest challenge now is remembering to implement data protection before something unexpected inevitably results in critical data sets suddenly becoming unavailable.