Cloudera Taps Kubernetes to Automate Cloud Data Flows
Cloudera this week launched a Cloudera DataFlow for the Public Cloud offering that employs Kubernetes to orchestrate the data flows required to process streaming workloads on the Cloudera Data Platform.
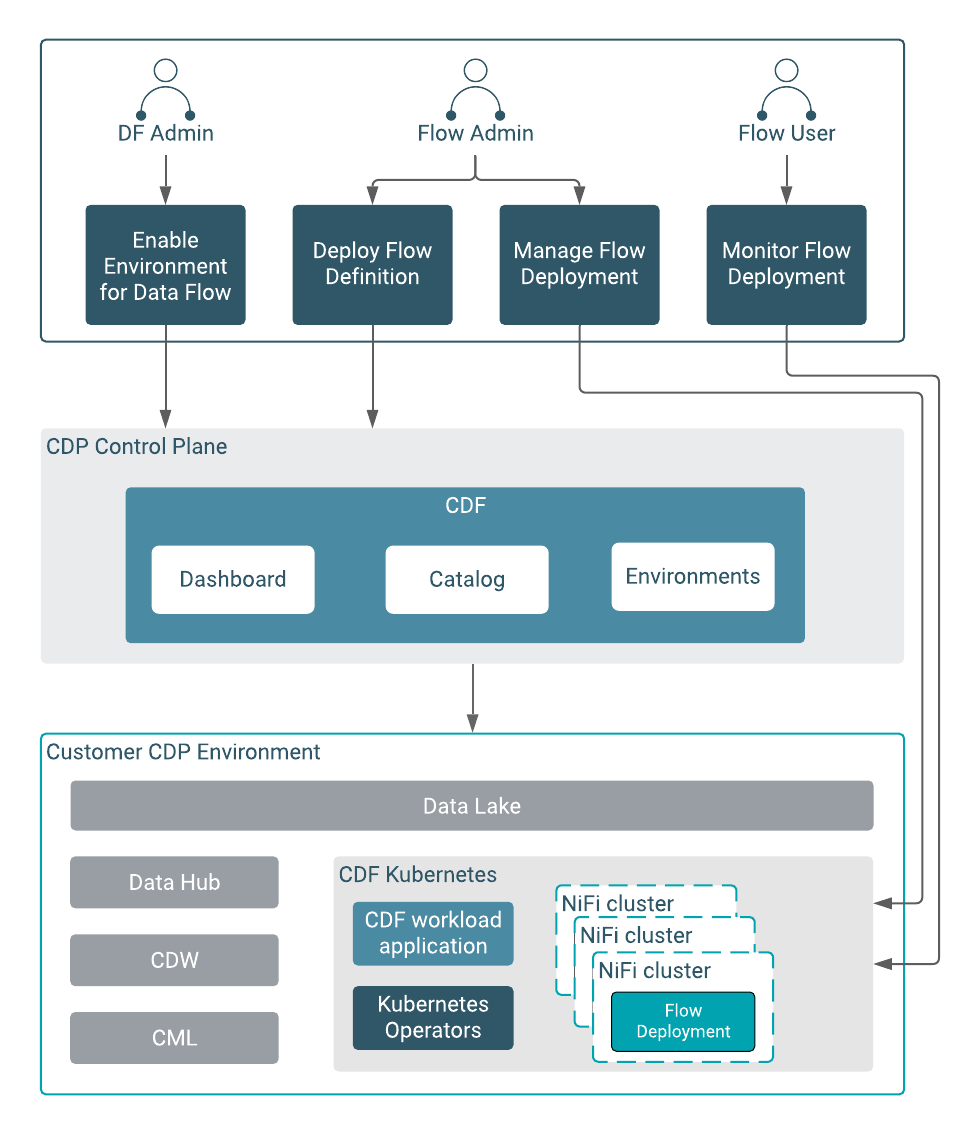
Initially, Cloudera DataFlow for the Public Cloud is available on the Amazon Web Services (AWS) cloud and provides IT teams with a visual no-code tool through which they can automate complex data flow operations in a way that allows them to automatically scale as required. It is based on open source Apache NiFi software that is being advanced under the auspices of the Apache Software Foundation (ASF). Apache NiFi itself is deployed on top of a Java virtual machine (JVM).
Cloudera DataFlow for the Public Cloud builds on that core to provide IT teams with a central flow catalog for manageability, discovery and version control. There’s also a central dashboard for monitoring, troubleshooting and performance tuning of data flows across multiple cloud clusters.
Finally, pre-built flows for common streaming use cases along with a deployment wizard that simplifies setup of the Cloudera DataFlow for the Public Cloud are also included.




Dinesh Chandrasekhar, head of product marketing for data-in-motion at Cloudera, says that approach provides the added benefit of eliminating the guesswork that is typically required to right-size cloud infrastructure to process data flows at the lowest possible cost. Many organizations that deploy Apache NiFi wind up overprovisioning cloud infrastructure resources, he notes.
Cloudera DataFlow for the Public Cloud will be made available on Microsoft Azure public cloud next, adds Chandrasekhar. Pricing for Cloudera DataFlow for the Public Cloud is based on “T-shirt sizes” that align with the amount of cloud infrastructure consumed, he says.
IDC forecasts that data-in-motion volumes will grow as high as 79 zettabytes across all industries. As the amount of data flowing into the public cloud continues to increase, IT organizations are hiring data engineers to construct pipelines that enable various types of data to flow into specific cloud environments. Cloudera DataFlow for the Public Cloud makes it feasible for IT administrators to also construct data pipelines using a drag-and-drop tool, notes Chandrasekhar.
It’s not clear what the right mix of software engineering skills will be required to drive data operations (DataOps) as the amount of data flowing from, for example, edge computing platforms continues to grow. It’s still early days as far as adoption of edge computing platforms, but in general, the goal is to process and analyze as much data as possible in real-time at the closest point to where it is created and consumed. The aggregated results are then shared with a systems-of-record application running in the cloud that might be accessing data stored in the Cloudera Data Platform.
Regardless of approach, Kubernetes will play a key role in enabling cloud infrastructure resources to be consumed more efficiently at a time when many organizations are trying to rein in cloud costs. The challenge now is just waiting for other providers of data management platforms to follow the same lead as Cloudera.