Advanced Deployment Patterns With Argo
A few years back, Adobe made a strategic move to embrace Kubernetes, helping engineers to develop and release applications that are portable across clouds. Teams have embraced K8s and have seen an increase in scalability and availability as well as a decrease in costs. As a side effect, over time we have seen a multitude of CI/CD technologies being employed, along with a large amount of homegrown code, all to handle the deployment infrastructure.
In its quest to reduce the technology sprawl and allow engineers to accelerate other initiatives, Adobe is moving toward using a common platform for CI/CD based on Argo projects. The choice is mainly due to the modularity of the projects, the native support for Kubernetes, the shallow learning curve and the easy setup.
Our team was a long-time Spinnaker user. We relied on it to build continuous deployment pipelines for numerous projects over the years. But we’ve also met some challenges along the way. When Adobe decided to build a CI/CD platform on top of Argo, we jumped at the chance to switch to GitOps and Argo. The main reasons were the self-healing option that comes with GitOps—we had been affected by this in the past—as well the reduced complexity that comes with using native K8s objects as opposed to using the Spinnaker APIs and UI.
However, our switch to Argo has not been without its own challenges. We’ve had to shift our way of thinking to a new paradigm, GitOps, and adjust to Argo’s realities. For instance, Argo does not provide automated promotion nor automated rollback out-of-the-box. Previously, we had taken these features for granted. Now, we had to adjust and implement these features using Argo Workflows.
Promotion and Rollback
So we rolled up our sleeves and built a workflow that automatically promotes a commit from Dev to Stage and from Stage to Prod. The decision to promote is based on health checks and tests, with the latter being executed on a PostSync hook.




The deployment logic is quite simple for each environment:
- The workflow promotes the commit to the environment by committing the new application version
- The workflow then triggers a sync of the Argo application and waits for the sync to complete successfully, ensuring that the Argo application state is healthy
- A PostSync hook triggers a Kubernetes job, which executes a suite of functional tests against the updated environment
- Provided that the job completes successfully, the sync of the Argo application will return successfully and the workflow will proceed to the next environment
In an ideal scenario where every environment is updated successfully, the result will be that the just-deployed application version will have been committed for every environment.
So what happens if something goes wrong during deployment? This is where automated rollback comes into play.

Let’s say that the deployment pipeline successfully deploys in Dev, but it fails in Stage because tests have failed. To rollback is to revert two commits: The one for Stage and the one for Dev.
So how does this happen? As we mentioned before, the tests are executed on a PostSync hook. If the tests fail and the job that runs them completes unsuccessfully, then the sync phase will have failed. In turn, this will make the Sync and Wait task fail in our workflow. At that point, the workflow will also be considered failed. When does the rollback happen, then? Well, we use an exit handler that gets called when a workflow is done, successfully or not. The exit handler checks the workflow state; if failed, it retrieves all the commits made by the workflow and reverts them.

Even if the continuous deployment pipeline contains quality gates and functional tests, it is possible (even if improbable) that the changes being deployed might contain a difficult-to-spot bug. Even the shortest of failures may have a huge impact on critical applications such as data collection. So how do we further ensure that we minimize the risk of failure?
Preview Environments
Even if the continuous deployment pipeline contains quality gates and functional tests, it is possible (even if improbable) that the changes being deployed might contain a difficult-to-spot bug. Even the shortest of failures may have a huge impact in critical applications such as data collection. So how do we further ensure that we minimize the risk of failure?
One pattern we’ve been using for many years is to create preview environments for every open PR. So how does this work? It’s simple, really. When a PR is first opened, we build the code and then deploy the PR code into a dedicated on-demand environment. The environment is partially or fully isolated—this depends on the nature of the application. It allows us to validate the PR in isolation before we consider merging the code.
Progressive Deployments
The combination of preview environments and post-deployment tests makes for a solid verification. We can deploy code and automatically test it before it’s even merged in the mainline. Yet sometimes there are error scenarios or even verifications that can only be done over time in real-world environments. So how do we handle these cases and further minimise the risk of failure? The first thing that comes to mind—and probably the most familiar to you reading this—is using a progressive deployment with Argo Rollouts.
This consists of a progressive rollout into prod environments with the rollout steps gated by validations and analysis. For instance, we might route functional tests to run against canary replicas and use them to validate the canary deployment. This works well for applications exposing HTTP APIs. For streaming applications, we can perform an analysis and decide whether to promote the canary or not based on processing metrics. Or we can even do a combination of both.
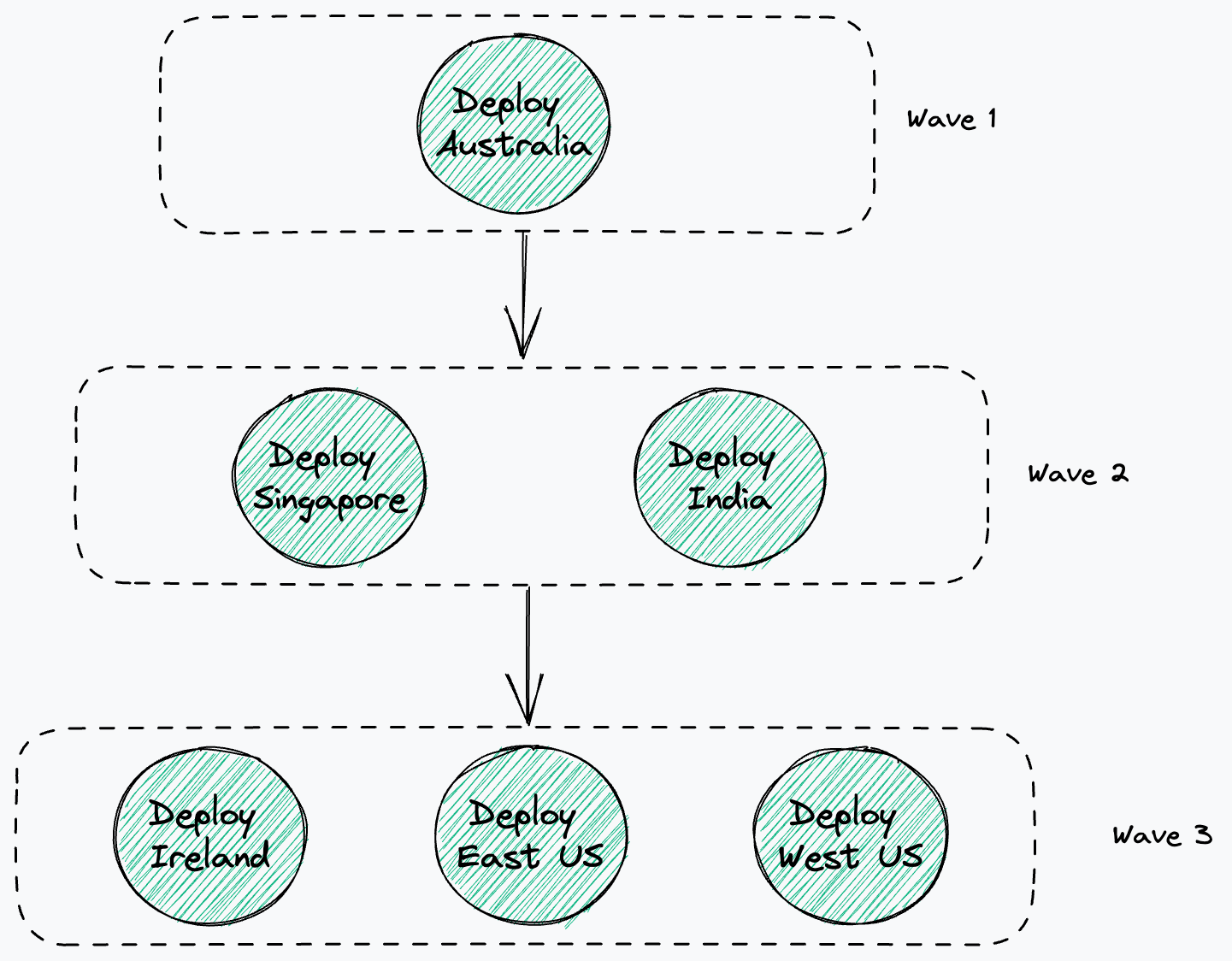
Wave Deployments
In Adobe, many services are deployed around the globe. The Experience Platform Edge Network, for instance, is deployed across seven regions. Deploying the edge services in all regions at once could have a big impact in case of an application defect. Difficult-to-spot problems may lurk in code changes; if the changes are rolled out simultaneously across the entirety of an application’s deployments, this could spell disaster.
So how do we reduce the blast radius? Deploying in sequence is far from ideal, as it would make the deployment unnecessarily long. The solution is to deploy in waves. That is, split the deployments into multiple waves, where each wave contains one or more geographies.
The idea is to minimise the blast radius by starting the deployment in an initial wave limited to one or two regions. How you select these initial regions depends on the application context, of course; one way to skin it is to deploy based on number of customers/users and letting the build bake for enough time to build confidence. For example, deploy first in a region where you have the least number of users so that the impact is minimal in case of a defect in the deployment.
If the initial wave is successful, you can continue with a second wave of deployments in other regions and so on. By deploying in waves, you can restrict the impact of bugs that have not been surfaced by functional tests and canary analysis to the fewest users. In case of failure, you can roll back the entire set of regions that have been deployed.
You could take this a step further: The first wave could consist of a dark launch. The way we do this at Adobe is that we deploy the code into a dedicated pre-prod environment using a prod configuration that doesn’t receive any real traffic. The environment receives synthetic traffic generated by functional tests and is used to validate the code in a production-like setup.
A Step Back From Continuous Deployment
We are great supporters of continuous deployment. In fact, we’ve been successfully using continuous deployments for years. It has helped us deploy quality code with greater confidence. It also helped us sleep well at night since we’ve had fewer incidents over the years.
Yet, we realize that continuous deployment doesn’t fit all use cases. There are real-world scenarios when continuous deployment just doesn’t work for a team. It may be that the deployment takes a long time—perhaps a slow canary rollout to production is needed to capture critical business metrics or the deployment workflow needs to perform many tasks. If the deployment takes a long time (e.g. 30 minutes or more), then deployments will queue. You can’t expect developers to wait for hours to get their changes deployed.
It could be that you have a large team working on a single repo and the frequency of commits to the mainline is high. Or maybe the business context requires that deployments follow a certain cadence—say, daily or even weekly.
How do we handle this situation? In these scenarios, using continuous delivery is a better choice. It requires the same diligence and emphasis on quality as a continuous deployment model, as it mandates building artifacts that are releasable at any point in time, just like a continuous deployment model. The difference is that you don’t deploy every change to production. The deployment to prod becomes a separate action that can be taken at a later time, depending on the team’s deployment strategy. One pattern we’ve explored:
- Deploy commits as part of a regular promotion workflow all the way to pre-prod environments;
- Deploy to prod “out-of-band” on a schedule, deploying the latest commit in the main branch.
Putting it All Together
By employing these practices, you can build deployment pipelines that are stable and reliable so that deployments to production are nothing out of the ordinary. While the migration from Spinnaker to Argo has not been without its challenges, we’ve managed to build the same kind of robust workflows on top of Argo and evolve them further.
Larisa Andreea Danaila, senior computer scientist at Adobe, co-authored this article.
Want to find out more and see some code? During our session at ArgoCon 2022, “Harder, Better, Faster, Stronger Pipelines @ Adobe,” we’ll go into more detail and show code examples of how to implement these patterns with Argo. ArgoCon 2022 runs from September 19-21, 2022.