A Pragmatic Guide to Container Security
Developers have long been chasing the dream of being able to write an application once and having it run anywhere. Despite valiant attempts over the years, we’ve never quite succeeded.
But over the past few years, we’ve come closer than ever. The meteoric rise of Docker from a simple idea in 2010 to a major player in a new infrastructure space is proof that containers have pushed through the Trough of Disillusionment and are slowly moving up to the Plateau of Productivity.
Containers have come a long way from their humble chroot beginnings.
Simple Deployments
The core goal of a container is simple: be a self-contained unit of computing.
The idea is that once created, a container will run the same way on your laptop, in your data center and in the cloud. By using a standard packaging format (a container), this solution finally tackles the age-old developer problem, “It worked just fine on my machine!”




Each container should contain everything it needs to complete its task, and only those things. Extra services and software should be reduced to an absolute minimum. Containers are lean and mean and follow the UNIX philosophy of “Do one thing well.”
Need to run that cool new vision application you just built? Your container should contain all of the required dependencies. So Python 3.6.5, pandas 0.23.0, OpenCV 3.4.1, and whatever else you need should be deployed inside the container.
That way the application won’t break if the virtual machine in the data center is running an old version of OpenCV, pandas or Python. Containers not only provide portability, but also isolation.
If we need version 1 and version 1.1 of our application running side by side, we can do that, since each version will be running in its own separate container.
Application Growth
As your application grows in complexity, it’s tempting to keep putting more and more into your containers. If you take this approach, your container will eventually resemble a full virtual machine.
Virtual machines are similar to containers in that they can provide isolation and contain all of the required dependencies for an application, but they are also heavy. They contain an entire operating system that requires maintenance. They reduce efficiencies by running multiple copies of the same services on shared physical hardware.
For containers to be an improvement over virtual machines, they need to stay small and focused.
But as applications grow, a single container will no longer suffice. This is where an old design pattern, Service Oriented Architecture (SOA), comes back into play with a shiny new name, microservices.
Microservices is the modernized concept of a collection of loosely coupled services being pulled together to form an application.
Container orchestration tools allow applications to be deployed in this manner easily. Implementing this design pattern is significantly harder using virtual machines and other deployment methods.
It’s an area where containers shine.
Infrastructure Costs
But containers aren’t all upside. Deployment methods for the containers themselves are relatively simple, but there is infrastructure complexity throughout the stack.
The difference is that the complexity has been pushed lower down to provide an abstraction layer (the container runtime) that containers can work from.
In stark contrast to the simplicity of containers, the infrastructure to run them is significantly more complex than that of virtual machines. That complexity has a cost and—as with all costs—that bill eventually becomes due.
This explains the push to run containers in the cloud. The major cloud providers all offer a variety of container-based services. From hosted infrastructure to high-level managed services, each offers some level of relief from these infrastructure costs.
While this relieves some of the infrastructure burden, it also creates a new challenge with hybrid environments, or at least multiple environments, where one organization deploys containers.
And this is without factoring in the data layer for most applications …
Data Stores
Containers have more than enough upside to counter the overall downsides. Remember, organizations need to evaluate the use of the technology beyond just the development team. A holistic viewpoint is a must.
When it comes to application deployment, containers are a clear win. With data stores, it’s no longer a slam dunk.
Most data stores (RDBMS, NoSQL and others) have built-in clustering and scaling systems. Some of these require very specific infrastructure that might not be compatible with your container environment.
All data stores will have volume management challenges that the container ecosystem has only recently matured enough to deal with.
This isn’t new territory. Virtual machine deployment also needs to deal with these challenges as well. The move to managed data store services benefits both application deployment models, as managed services tend to provide much higher performance for the level of effort required.
Landscape
Pulling this all together, we see that containers are a great way to simplify application deployment. But given the diversity of applications, we end up with the following landscape: Containers deployed as individual workloads or as a group forming a complete application running locally on an endpoint, in a data center or in the cloud, and may or may not have large volumes of data dynamically attached.
This diversity of deployment models makes for a very challenging security puzzle. How do we apply the appropriate controls at the right time and in the right place?
Traditional approaches dictate that we should try to control as much of the landscape as possible. This runs directly counter to the flexibility that containers provide development teams.
What is a modern, programmatic way to integrate security into our container deployments?
The Goal of Security
Most people think that the goal of cybersecurity is to stop hackers. That’s definitely part of the challenge but it’s also too narrow a definition. The true goal of cybersecurity is to make sure that your systems work as intended—and only as intended.
This definition requires that security works with the business.
When it comes to containers, working with the business means providing the necessary controls to ensure systems are working correctly while not slowing down the development process.
To accomplish this goal, we need to take a step back and start to apply security concepts earlier in the development process.
We need to “shift left” when it comes to security. This means starting at the planning stage of the development cycle and working security deeper into the stages of development before things are pushed to production.
Development Cycle
Quality, resilience and security go hand in hand. At each stage of development, the goals of the development, operations and security teams are aligned, even if they aren’t working together.
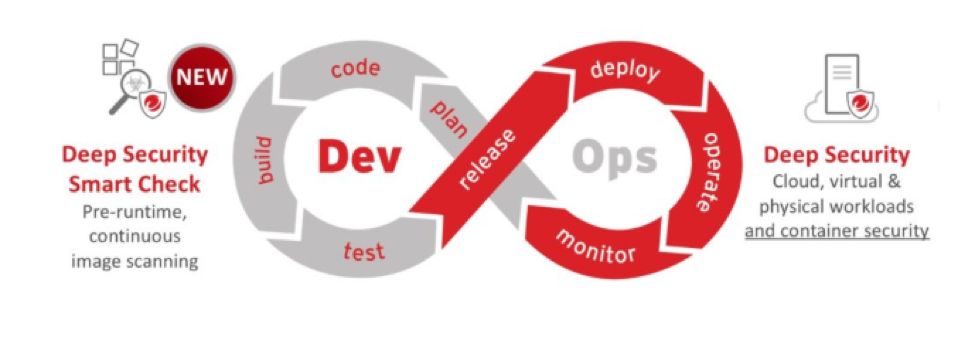
Addressing security issues during the planning stage (step 1) is the easiest and least expensive way to improve the overall security of the application. But mistakes are made, issues pop up and any number of unexpected challenges arise during this stage as well as when you’re actually writing code (step 2).
At the end of the coding phase (build time), and throughout the testing phase (step 4), the first opportunity arises to add a security safety net to improve out builds.
Build/Test
Applications are rarely built entirely from scratch. Third-party libraries, previous projects, cloud services and other containers are pulled together to create a new application. After all, why reinvent/rewrite the wheel?
The downside of these building blocks is that they can also have issues.
You need to ensure that these issues are identified and any risks mitigated. A strong approach here is to scan these blocks for vulnerabilities, malware and configuration errors.
In a container workflow, you can accomplish this goal by instantiating your container and scanning for these issues. Finding an issue doesn’t have to stop your process, but the issue does need to be evaluated for the risk it poses.
Can you simply fix the issue? Can you mitigate the issue using a control somewhere else? Should you just accept the risk?
Each case needs to be evaluated by your team.
Registering Your Container
With the build evaluated, you now have a container to deploy to production. This container is better understood, it is scanned and it contains code that has been tested.
It is signed and promoted to a container registry. Teams can pull containers from the registry to run in production.
Here, again, is an opportunity for a security safety net in the form of whitelisted containers.
The concept is simple: Unless a container has been approved by your process, it shouldn’t be running in production.
Implementation will change depending on your environment, but a popular method in a Kubernetes environment is to use an initializer. This is a workflow hook that allows for an evaluation of the container before it hits production.
Does it meet your policy? Is it from your preferred registry? These are the types of questions you can ask using an initializer. Of course, there are other methods. The key here is to be able to apply a technical control to ensure that only the containers that meet your policy are running in production.
Changes in Production
Once a container has been instantiated and deployed in production, it’s nice to think that things won’t change. Sadly, that’s not true.
As soon as a workflow is interacting with the rest of the system and your users, changes will be made. Log files written, caches created and managed, data stored in the back end.
The goal of security controls at this stage is to ensure that all of these changes are expected and within some range of “normal.”
Developers will do their best to ensure code is high quality and working as expected. But tools such as application control (allowing only specific processes to run), anti-malware (checking for malicious content) and integrity monitoring (checking for unexpected changes) are a low-effort/low-impact safety net.
Network Flow
With the containers themselves being monitored for abnormal behavior, it’s time to look at the network. The challenge with network security is applying the rights rules at the right time.
Perimeter defenses are great for generic rules. SQL injection, cross-site scripting attacks and other similar techniques are best stopped as far away from your workloads as possible. This is where a web application firewall (WAF) or perimeter intrusion prevention systems (IPS) comes into play.
However, the vast majority of attackers use lateral movement once they find an initial weakness. Again and again, the same pattern comes to light: Exploit a simple hole in one system, get behind the perimeter defenses and attack other systems to get as large a foothold as possible on the victim’s systems.
This is why security has adopted a principle called defense in depth (computing). Simply put, don’t rely on only one thing to stop a specific type of attack.
When it comes to network flow, strong access control lists (which system can speak to which other systems), network isolation (breaking up the network based on application requirements) and internal IPS deployments help reduce the risk that an attacker can move laterally if they make if through the defense at the edge of your workload.
Logging
No one sets out to get hacked, but smart teams play for the “eventually.” A critical step in planning is to ensure there is enough information to respond to any incidents.
You want to make sure you’re safely and securely logging as much actionable information as possible.
This is where cloud deployments really shine. Cloud service provider environments typically have a number of high-quality data processing and management services.
A smart logging strategy generates a ton of data. Cost is definitely a factor here, and one of the main reasons security information and event management (SIEM) systems haven’t been as widely deployed as they should be on-premises.
Working with the development, operations, security and business teams is important. Everyone is interested in the same data, just with a slightly different point of view.
Your logging strategy should account for this to maximize its effectiveness while reducing costs.
Visibility
Systems are good are processing significant amounts of log data. Humans, not so much. This is where visualizations play a role.
Being able to quickly spot anomalies and abnormal behavior is far simpler using visualizations of the log data than by reviewing log lines.
Once an issue is identified, you can dive deeper into the specific log information.
Again, this is a step where collaboration across all teams pays off. Almost all of the data used in security is also useful in a business context. The same holds true for operational and development data.
Creating a single, unified way of collecting, processing and visualizing the organizations data should be high on everyone’s list.
With that in place, operational work that is considered “security work” is far, far simpler.
Next Steps
Security has long stood as it’s own discipline and has been applied in isolation. This has lead to mixed results.
Modernizing the approach to security and adopting a similar mentality to the teams leveraging technologies like containers opens up a fantastic opportunity.
Your security implementation can finally line up with your desired security outcomes.
Shifting left to take action earlier in the development cycle is all upside. Yes, it’s difficult given the current mindset, but the investment in culture change is worth it.
Containers aren’t the solution to every problem, but they do solve a number of significant issues around application development and deployment.
Take the time to understand how they are used.
By applying a pragmatic approach to container security, you can end up with a very strong, stable deployment that allows for that dynamic workflow that you have worked so hard to implement with your shift to a DevOps culture.