Best of 2021 – How to Implement Disaster Recovery for Kubernetes
As we close out 2021, we at Container Journal wanted to highlight the most popular articles of the year. Following is the thirteenth in our series of the Best of 2021.
Conventional wisdom used to be that a disaster recovery plan (DRP) applied only to services and/or platforms that your organization personally managed and/or operated. But, with the rise of anything-as-a-service (XaaS), many cloud providers and vendors provide container-as-a-service (CaaS) or Kubernetes-as-a-service (KaaS) offerings to make it easier for enterprises to run container workloads at scale. And while such offerings do have high availability service level agreements (SLAs) in place, cloud outages do pose a risk you want to mitigate.
Today, it’s more important than ever to invest the time in formulating your disaster recovery plan (DRP) for Kubernetes environments. Regardless of who manages the underlying platform, Kubernetes is becoming the de facto standard for running cloud-native applications, and that means you should have a DRP for Kubernetes environments.
Think about the Kubernetes like a railroad. It’s the backbone of rail transport, and, therefore, any railroad delays and accidents can have a catastrophic economic impact far beyond the single delay or incident. Similarly, if you’ve decided to run your business applications in production in Kubernetes, you can’t overlook the potential impacts of an outage or security incident. It’s not a matter of if, but when an issue will occur.
A DRP doesn’t have to be a hundred-page document that no one understands. Certainly, you want to have runbooks and playbooks to guide your team through the different tasks that make up the plan; however, the plan itself should be simple. Highlight what should be done, and by whom, on what timeline to meet the business’s needs and get back online as quickly as possible.



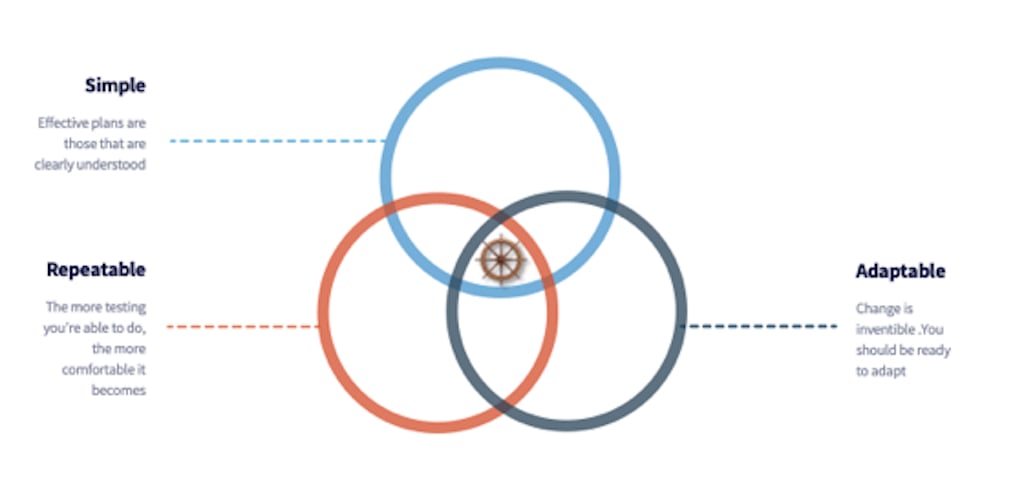
There are three essential characteristics of an effective DRP for Kubernetes environments: simplicity, repeatability and adaptability. These characteristics are all interrelated. Having a plan that meets these standards will save time, money and get you back online effectively.
1. Simplicity
Let’s face it, becoming cloud-native is challenging. In a crisis, you want to make it easy for your team to follow the steps in the plan and get back online. There are five key decisions you have to make when creating a DRP.
- What is your disaster recovery strategy?
- What is the recovery time objective (RTO)?
- What is the recovery point objective (RPO)?
- How is traffic routing handled?
- What is essential for backup?
Usually, a disaster recovery strategy will involve one of the following:
- Backup and restore
- Active standby
- Active active
Each strategy has its pros and cons. You want to carefully assess your business application SLAs and budget to help you determine the acceptable RPO and RTO.

In a nutshell, RTO is the downtime you’ll endure before getting back online, and RPO is the amount of data you can afford to lose due to an outage measured in time. For example, an RTO of 15 minutes and an RPO of 5 minutes means that you have to get back online in 15 minutes or less, and can’t afford more than 5 minutes of data loss due to the outage.
The smaller the RTO/RPO, the quicker the business can get back online to serve its customers, but the higher the costs. Determine such objectives carefully.
In terms of traffic routing, you want to make sure you’re able to failover to a new cluster (or a standby cluster, if you choose an Active standby strategy). This can happen manually or automatically by altering DNS entries and your global site load balancer (GSLB).
When it comes to backups, you want to consider all the different components of Kubernetes including applications, infrastructure and data. Here’s a quick overview of each of these components.
Containerized applications are made of :
- Images: These are the container images that define what operating system distribution and libraries are required for the application to run.
- Kubernetes Objects: These are pods, deployments, services or ingresses associated with the applications.
Applications
- Image Registry
- YAMLs
Infrastructure
- Cluster nodes
- Custom configurations
- etcd
Data
- Stateful applications data (block, object, etc.)
- Databases
Depending on the topology of the cluster, business applications SLAs and the RTO/RPO of your plan, you may or may not want to back up the etcd datastore and/or the underlying hosts.
A simple and easy way to back up all the resources (i.e., YAMLs) in your etcd datastore (pods, deployments, ingresses, etc.) is to run the following command:
![]()
Running this command should give you a snapshot of the current state of all Kubernetes objects of the cluster. This doesn’t include certificates, any of the data stored locally on the worker or master nodes.
You can regularly run this command during less busy times and push the output YAML to your Git repository. This has two benefits. It gives you a snapshot of the current state that you can compare and contrast over time, and it serves as a backup of your resources that you can use should you decide to spin up a new cluster during a disaster to get you back online.
2. Repeatability
A DRP is only as effective as the ability to repeat the steps in it. You should regularly run drills to simulate a disaster situation. This will enable you to assess your preparation, learn how to integrate any changes or updates you made since the previous drill, keep team members’ training current and regularly review and update the plan.
Practice makes perfect. The more you’re able to conduct DR testing for your Kubernetes environments, the more confident you and your team will be in your ability to handle a disaster when it occurs.
While it’s not always possible, automation is a key for DR testing. Leveraging infrastructure as code (IaC) and using a software configuration management system can make it easier to codify infrastructure, make fewer mistakes and recover faster.
Before conducting DR testing, choose an environment that is as close as possible to your production environment in terms of the architecture, configurations, etc. Some organizations have very sophisticated DR plans that can handle, for example, deleting all production clusters with minimal end user impact.
Operator skillset is an important part of a DRP for a couple reasons. First, you should be able to automate as many of the plan’s steps as possible using homegrown scripts or other tools. Second, the ability to learn and adapt fast as things change – and they will change, with every drill you conduct.
Finally, you want to assess the user impact on the selected environment beforehand and make the proper announcements ahead of time. This will help everyone be on the same page, and make DR drills a non-event as you conduct them more regularly.
3. Adaptability
Whether you’re moving workloads from the public cloud back on-premises, going multicloud or going beyond a single cluster, you will want to make changes to your plan at some point.
Depending on how you formulated your plan, you should easily be able to integrate changes. Always think long term and make sure the most recent version of the plan is clearly understood by everyone. Start with a simple plan and add on as environments become more complex.
Here are few things to keep in mind to make your plan more adaptable:
- As you determine the disaster recovery strategy and make key decisions, question everything.
- Build in modular automation so that it’s easy to use plug-ins or modules.
- Document all changes you make to the plan and why those were made. This makes it easier to reference.
- Conduct drills to make sure the changes’ impact is minimal, and that everyone understands the changes.
Failing to plan is planning to fail. While IT infrastructure today is more robust than it was years ago, systems are more complicated and distributed than ever before. An effective DRP is simple, repeatable and adaptable. And while there’s no such thing as the perfect plan, you can start from where you are, adapt, and learn as you go. While a DRP is not something you’ll execute daily, it’s of paramount importance when disaster does strike.