Kubernetes Pipelines: Hello, New World
Kubernetes pipelines are about to change the way we do things. Kubernetes and microservices will drive us away from our old way of doing things to a much leaner method of software development. And when I say a Kubernetes pipeline, I’m not referring to a particular set of tools; rather, I’m exposing the difference between what we do in a monolithic pipeline versus a Kubernetes pipeline process. I’m not convinced that the Kubernetes pipeline has been solved. We have some work to do.
Kubernetes and microservices is not just disrupting how we create, manage and access software, it is obliterating it. We have not seen a change like this since the enterprise transformation from mainframes to PCs. This move is being driven by two primary features of the Kubernetes architecture: fault tolerance and high availability with auto scaling, both required for creating modern software that can satisfy consumers’ demand for more data faster. IoT, big data, machine learning and AI all require the bigger processing power, stability and responsiveness offered by Kubernetes.
When I say Kubernetes is a shift as big as the move from the mainframe to distributed platforms, I’m not exaggerating. Kubernetes and microservices will force development practices to move away from our old monolithic pipeline habits to a new Kubernetes pipeline process supporting real continuous development.
Let’s first look at a monolithic pipeline, because it is very different from a Kubernetes pipeline. When we develop software in today’s pipeline environment, we pull together custom code, shared internal libraries, open source objects and database components. The application is written with an infrastructure in mind, such as a particular version of Oracle and Tomcat. The first step in our monolithic pipeline habit is to compile the application, often called “the build.” Our build scripts perform the magic of creating the binaries—they pull source code into a local build directory, point to compiler libraries and other directory locations for other required libraries, compile the objects and create the .jar, .war. and .exe files that are to be deployed. In some cases, we must run multiple builds to update configuration info that is specific to an environment (dev, test, prod).
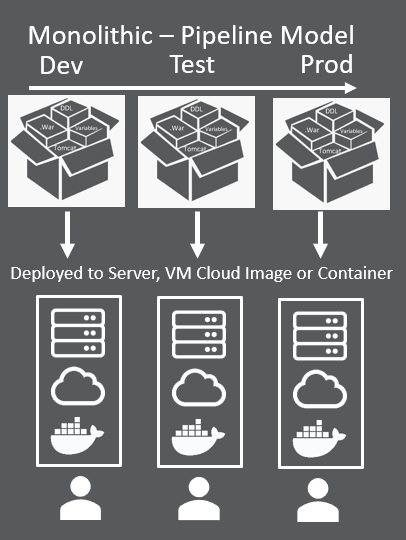
When we do the release, we send all the objects from the build. The build is monolithic; therefore. the deployment is monolithic. When we deploy, we update physical servers, VM images, cloud images or a Docker container with the entire set of objects from the build. Our continuous delivery pipeline orchestrates this build and release process, centralizing the logs and pushing the process from dev to test and test to prod. A Kubernetes pipeline will look very different. Even the concepts of dev, test and prod environments goes away eventually.




![]() OK—did your head just explode? Good—now you have an open mind.
OK—did your head just explode? Good—now you have an open mind.
Microservices offer a completely new way of approaching software design and deployment, one that is truly continuous. It fits extremely well into an agile methodology where all dev, test and prod specialist are all on the same team, and the goal is to drive innovation via smaller incremental updates that happen daily. This is the goal of a Kubernetes pipeline. The concepts of siloed environments and our old monolithic pipeline habits begin to fade as microservices move us into a truly continuous practice. Our monolithic application is broken into individual, independently deployable services. A single microservice alone only performs a highly specialized function of the application. A collection, or package, of microservices becomes equivalent to your monolithic application, but you rarely release in terms of the entire application.
In some cases, teams moving to microservices will still manage applications in a monolithic style. Each version of the application will be deployed to a siloed Kubernetes cluster. But while this may work in the beginning, it does not take full advantage of the power of Kubernetes.

As teams developing on Kubernetes gain more experience, they will begin moving away from these silos. Service mesh will become part of the Kubernetes pipeline and will be used to perform the request routing to control user access to microservices. All end users will be defined to use the ONLY cluster, which will contain multiple versions of a single microservice to serve dev, test and prod end users. A new version of an application will be deployed that brings with it ONLY a new version of a microservice—v2, for example. The Kubernetes pipeline will instruct service mesh to route some users (dev or test) to access the application that includes the v2 of the microservice. Once approved to be released, service mesh will do the routing.
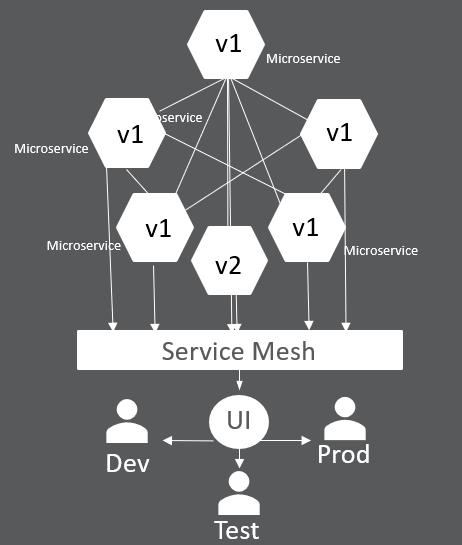
When this becomes the norm, teams will be able to quickly perform an incremental update of an application and deploy it just once. When the new microservice (which creates a new version of the application) is ready for prime time, the Kubernetes pipeline will instruct service mesh to route all users of the application to begin using the v2 of the microservice. Now you can see how our traditional monolithic pipeline (dev, test, prod) becomes a bit blurred, or maybe just a bit more continuous, and more agile. A rollback is simply an instruction to the service mesh to reroute users. A roll forward is the same. Builds and releases become much smaller as we begin focusing on the microservice, not he monolithic application.
There are so many questions that still need to be answered: For example, will each microservice have its own workflow? How do you aggregate the monolithic equivalent of an application? How do we version a microservice? How do we track relationships?
I know we have spent lots of time sorting out a lifecycle process to manage our monolithic pipeline, but eventually it must go. Kubernetes and the new Kubernetes pipeline is ushering in a much better way. Our job is to begin seeing this new way, and therefore begin breaking down the old patterns so a new, faster method of creating software is allowed. Just keep your mind open and together we will create a Kubernetes pipeline process that drives innovation to end users faster then ever before. It is about time.