Running Containerized Services on Kubernetes: What We Learned (Part 1)
At Magalix, we help companies and developers find the right balance between performance and capacity inside their Kubernetes clusters. So, we are big Kubernetes fans. We went through a lot of pain and learning cycles to make Kubernetes work properly for our needs. Those experiences also helped us a lot to empathize with our customers. Building fully containerized and building fully elastic Kubernetes managed microservices is difficult and still requires a lot of legwork.
We have been using Kubernetes for more than a year now and what I’m sharing here are some highlights. Feel free to ask questions about your specific situation in the comments below. I’ll be happy to share how we solved similar problems in our infrastructure.
Kubernetes: High-Level Goals and Architecture
Our service provides resources management and recommendations using artificial intelligence (AI). Our AI pipeline consists of time series predictions, scalability decision analysis, optimization and a feedback loop to learn from these decisions. These are mostly offline systems, but we also have real-time systems that interact with our customers clusters via installed pods. Our systems must have high availability with very low latency for a quick response to scalability needs. We also provide a one-stop service wherein users can manage many distributed clusters at different geographies and cloud providers.
With those goals in mind, we decided to have multiple Kubernetes clusters organized in a hierarchical way.
- The Magalix agent is resilient to network failures. Magalix’s Kubernetes agent must always be connected and resilient to network failures.
- The global entry points should be geo-replicated across different providers to guarantee highest possible availability to our users and internal dependent systems.
- The AI pipeline is super efficient. Our AI services have different capacity and availability requirements that require bursts of compute needs. We must be super efficient to make AI-based decision making affordable to our customers.
- No cloud vendor specific service dependencies. We should be able to extend our infra easily to any other cloud provider with no major architectural or dependencies changes
To achieve these goals, our infrastructure ended up having multiple Kubernetes clusters inside our virtual private networks with only one secure endpoint accessible to deployed agents.



Regional Backend (BE) cluster collects metrics data and sends back recommendations to agents for execution. These are distributed and highly available clusters across different regions and different providers.
Regional AI clusters are setting close to the regional BE clusters to guarantee low latency of metrics predictions, and the ability to generate scalability decisions fairly quickly. It imposes a challenge for sharing training data and deploying back updated models. I will discuss these challenges it in a separate post.
Global Backend (BE) cluster is responsible for two main tasks: (1) aggregation of account level data across different customer clusters, which includes performance, decisions accuracy and billing data. (2) A single endpoint for our users to access APIs and the web console. This cluster is also geo-replicated with very low sync latency.
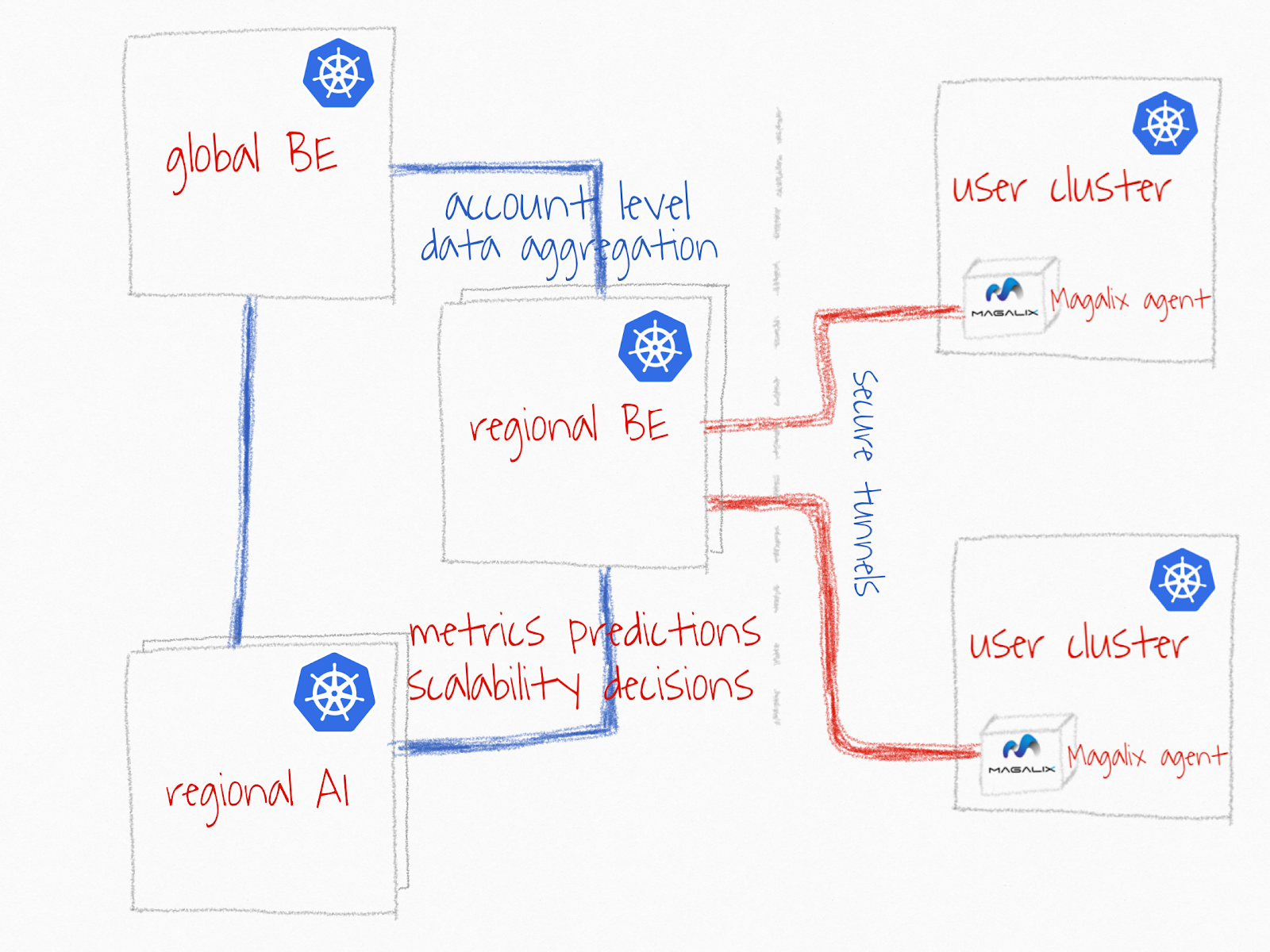
Clean abstraction of infrastructure in the Kubernetes world is a myth. Dependencies between workloads, containers, application architecture, capacity and infrastructure always will be there but revealed and managed in different ways. Teams must be aware and have a clear mental model of how they should manage these dependencies.
We thought at the beginning that containers and Kubernetes would provide an easy and clean separation between infrastructure and back-end teams. Unfortunately, we discovered that this is not the case. We had lots of contention between infrastructure engineers and BE engineers on resources management, access rights and security management. I’ll share with you the roller coaster of resources management here and share the experience with access rights & security of Kubernetes in the next few posts.
Resource Management
We wanted to be super efficient from the get-go, so nodes allocation was done through a budgeting process to avoid having idle or underutilized instances. It was a shock for most team members when we decided to take this approach. After applying restricted resources allocation, we started to have OOM (out of memory) terminated containers, inaccessible (now smaller) nodes due to containers highjacking their CPU, unexpected eviction of pods, failed deployments and, of course, frustrated customers and team members.
We thought we knew the resources needed for each container and microservice, but we were really surprised upon further investigation by how much our configurations were loose. We realized we didn’t set the right request (minimum) and limit (maximum) of CPU and memory in many cases, which caused containers to unconditionally use nodes resources. We also discovered that we didn’t have a clear way to budget resources and manage trends of resources usage. For example, we were setting the requests of some pods much higher than what they use most of the day. We wanted to be ready for the spikes that happen once or twice a day, based on users patterns and behaviors. Sound familiar? We are back again to the VM allocation patterns, but at a more granular scale. It was a joke—and not a funny one, I might add! Part of our mission is to help others efficiently manage their infrastructure, yet we found ourselves challenged to achieve that efficiency internally.
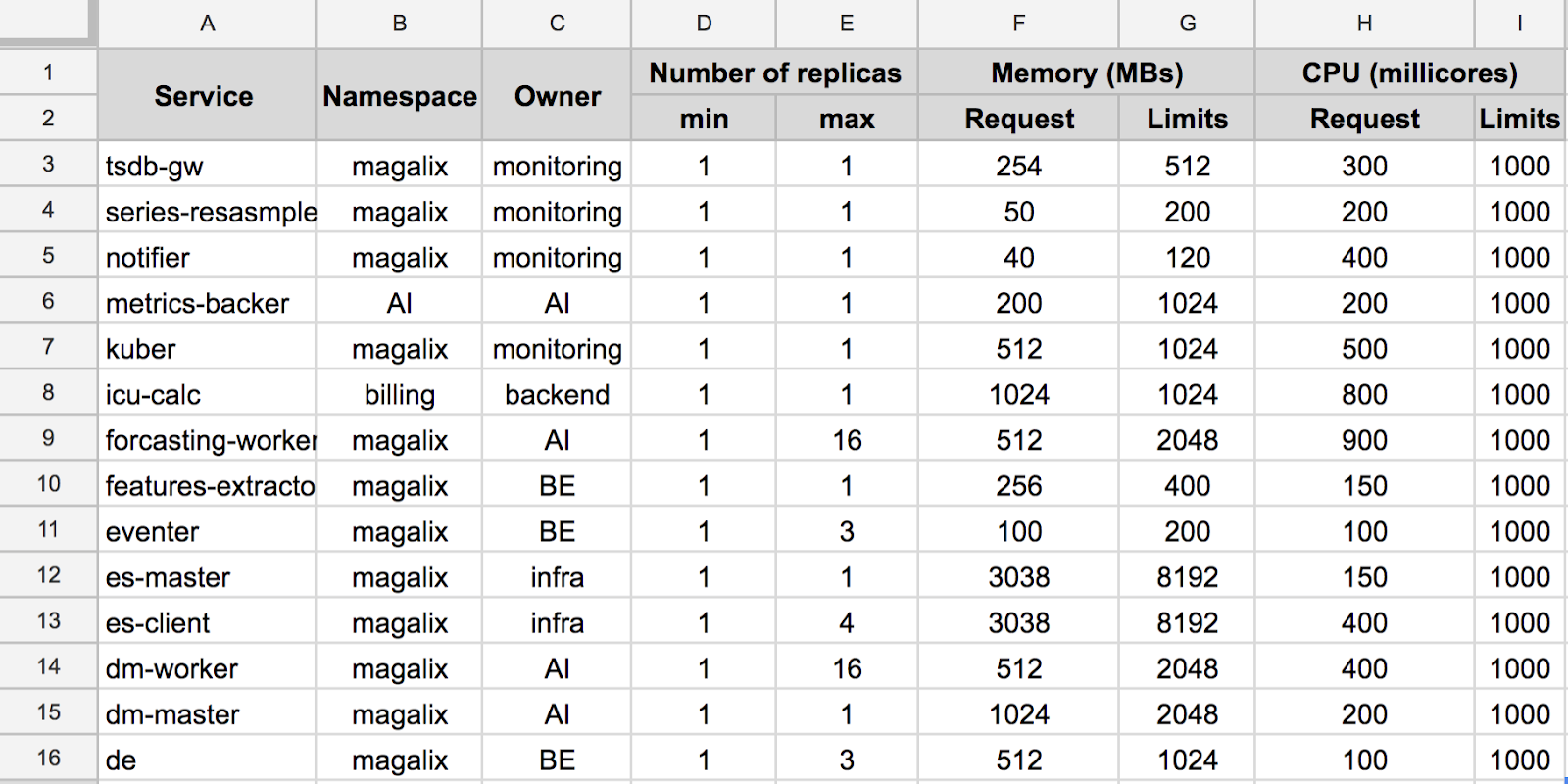
We decided to start with the dummy way. We created a document to list how much resources each service would need, as well as the minimum resources “request” and the max “limit” of CPU and memory. I was skeptical about this process, it but it was an eye-opener on multiple fronts. First of all, we discovered that the majority of our pods and containers did not have any CPU requests or limits set. Engineers were focusing only on memory. That was expected, since memory is the largest source of crashes and failures inside their containers. However, our infrastructure team and I were interested in the CPU limits. CPU misconfigurations where causing systemwide issues—the typical noisy neighbor issue—but the uncertainty of pods scheduling made it worse and random. We were having infrastructure live site incidents (LSIs) caused by one microservice monopolizing the CPU and suffocating other services sharing the node with it. This impacted our infrastructure services, such as CoreDNS and Calico, which exacerbated the problem. We left it to our developers to estimate their CPU needs. So, they went back to our dashboards to estimate how much CPU they would need, but it wasn’t easy, because the millicore concept inside Kubernetes does not consider the CPU type or power. For example, 100 millicores on m5.large is much less powerful than 100 millicores on c5.large. This is part of a future work in Kubernetes resources management. We decided to get started by just setting arbitrary CPU request and limits based on the services history—see below simplified budgeting snapshot.
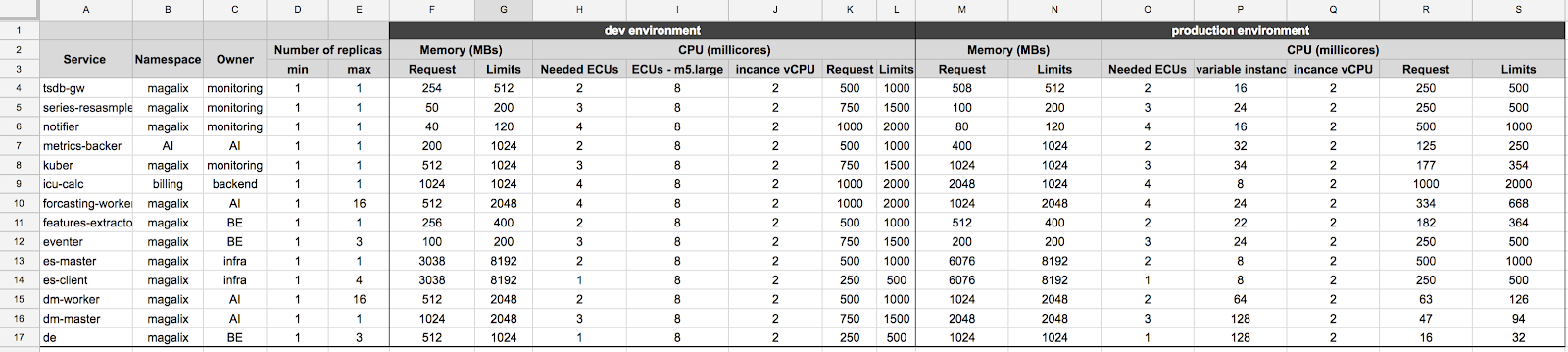
 We hit the same issue again when we deployed our services to production. Instance types and sizes are different in production environments and across providers. We wanted to make sure that we double estimated the right amount of millicores and memory when we promote our services from dev to production environments. So, to normalize from what we have in dev and project it to workload needs and available capacity in prod, we used AWS ECUs (EC2 compute unit) as the base to calculate millicores. Rather than expressing the needs in constant millicores value, we measured in the dev environment the reasonable millicores usage of each container and converted these to ECUs to know how many millicores we need as the container moves from one instance family to another. Remember, the goal is to have consistent performance and to make sure we don’t over- or under-provision resources.
We hit the same issue again when we deployed our services to production. Instance types and sizes are different in production environments and across providers. We wanted to make sure that we double estimated the right amount of millicores and memory when we promote our services from dev to production environments. So, to normalize from what we have in dev and project it to workload needs and available capacity in prod, we used AWS ECUs (EC2 compute unit) as the base to calculate millicores. Rather than expressing the needs in constant millicores value, we measured in the dev environment the reasonable millicores usage of each container and converted these to ECUs to know how many millicores we need as the container moves from one instance family to another. Remember, the goal is to have consistent performance and to make sure we don’t over- or under-provision resources.
For example, as shown in the below snapshot, the eventer container needed around 750 millicores on m5.large instance. This is translated to around three ECUs. To have a relatively consistent performance as we move it to production we know we need to its memory (which is easy) but we don’t need to really increase the CPU it uses. The eventer’s instance group is m5.xlarge. To give the eventer the same number of ECUs, this gets translated to 50 percent less millicores on m5.xlarge instance. It is tricky when it comes to moving containers to instances of different family. For example, its not straightforward to adjust millicores and memory if you run your container on t2 instances inside your dev environment, but want to deploy it to c5 instance type in production. But if we use ECUs as a reference point, we can model it and create a simple calculator. The problem with this solution is that we have to keep up with each microservice manually, and update it every time we either change instances types or resources allocated to pods.
Note: Drop me a line if you want me to share our millicore estimator sheet. We are working on a more elegant solution for this problem that we will share publicly soon. I wanted to share to see if someone else solved it a different way.
 The next issue we faced is the fluctuations in CPU and memory needs throughout the day, which is really a tricky problem. Changing the CPU may require pods to be restarted and rescheduled. We wanted to control two factors concurrently: (1) when vertical scalability takes place, and (2) whether the pod should be restarted or not. We also wanted to have more control over when a pod got rescheduled, and at which node it was going to run. The pod should to be scheduled to the best node family based on the pod’s profile. For example, one of our pods/services is balanced in CPU and memory most of the day; however, it does a nightly batch job that requires a lot of memory. This particular pod needs to be moved once or twice a day from m5.large to r4.xlarge. Doing so will save us more than 30 percent of our EC2 spending for only this one pod.
The next issue we faced is the fluctuations in CPU and memory needs throughout the day, which is really a tricky problem. Changing the CPU may require pods to be restarted and rescheduled. We wanted to control two factors concurrently: (1) when vertical scalability takes place, and (2) whether the pod should be restarted or not. We also wanted to have more control over when a pod got rescheduled, and at which node it was going to run. The pod should to be scheduled to the best node family based on the pod’s profile. For example, one of our pods/services is balanced in CPU and memory most of the day; however, it does a nightly batch job that requires a lot of memory. This particular pod needs to be moved once or twice a day from m5.large to r4.xlarge. Doing so will save us more than 30 percent of our EC2 spending for only this one pod.
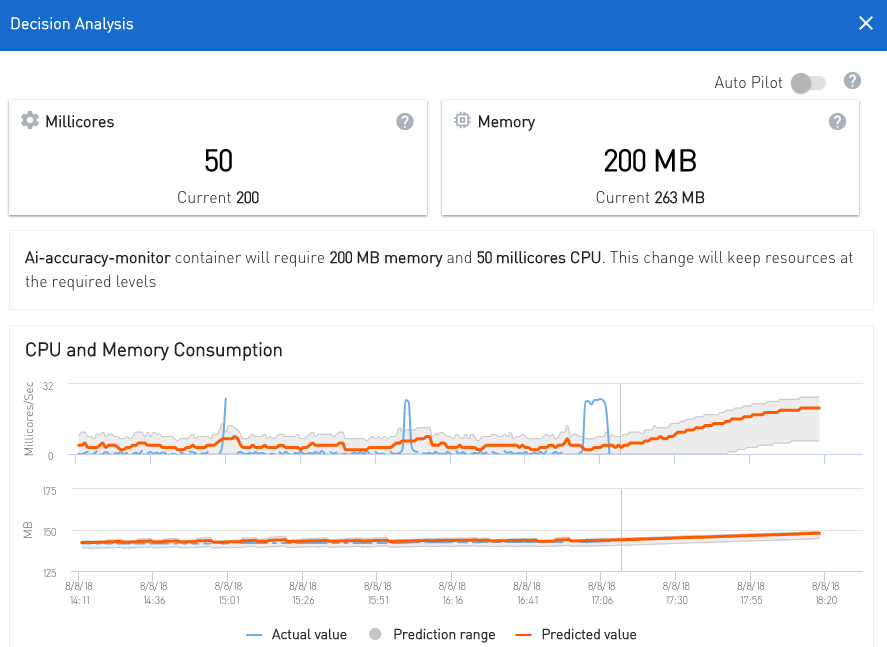
The first thing that came to mind to fix this particular issue was to use our own AI pipeline to get the future workloads predictions and estimated memory and CPU needs. We did some tweaks and started feeding in the CPU and memory metrics into our forecasting and decision-maker components. We were actually happy with the predictions being generated in a fairly short period. Our AI was able to predict memory and CPU needs for next two to four hours for each pod with 80 percent accuracy. This is based on recurring usage patterns we saw for CPU and memory—see snapshot below of predicted memory and CPU of one of our pods. A couple of hours after, we started getting decisions/recommendations to scale memory and CPU. Our AI models started to adapt to expected changes of the expected two-to-four-hour workloads—see below snapshot showing multiple decisions to scale memory only. CPU allocation was fine at that point.
A couple of hours after, we started getting decisions/recommendations to scale memory and CPU. Our AI models started to adapt to expected changes of the expected two-to-four-hour workloads—see below snapshot showing multiple decisions to scale memory only. CPU allocation was fine at that point.
 Note: the impact column is an estimated monthly saving if the decision is carried over and the agent change instance type. This is still an experimental feature in Magalix that is out of scope for the current topic, but I will talk about it in a different blog post.
Note: the impact column is an estimated monthly saving if the decision is carried over and the agent change instance type. This is still an experimental feature in Magalix that is out of scope for the current topic, but I will talk about it in a different blog post.
Note: VPA wasn’t really reliable enough to use at the time of this writing. Also, we wanted to have more control on when and how pods will be scaled, which is something VPA and HPA do not provide. Hence, we didn’t consider either as a potential solution.
Stay tuned for Part 2 of this series, which will cover access rights and security of Kubernetes.