Rancher’s Longhorn Project Brings Distributed Storage to Kubernetes
Rancher is expanding the scope of its Longhorn Project by extending the distributed storage platform to support all available Kubernetes clusters, as the open source software firm continues to bet on Kubernetes’ continued massive-scale adoption.
Rancher began Project Longhorn after Rancher began to offer persistent storage for its open source container management platform over a year ago. The underlying concept consists of developing a platform that offers distributed block storage for otherwise stateless microservices running on cloud and container deployments. The ability of Rancher’s Longhorn to offer distributed storage to run on Kubernetes is an obvious next step, says Sheng Liang, co-founder and CEO at Rancher Labs.
“Kubernetes is everywhere. Every cloud services provider supports it,” Liang says. “What we are saying now is that even a storage infrastructure can be deployed on Kubernetes.”
The announcement follows Rancher’s plans to make the final production version of Rancher 2.0 available this month. Rancher sees Longhorn as a way to extend the power of Kubernetes technology by using it for storage containerization.
Rancher developed Longhorn as a way to make distributed storage systems less complex thanks to the light designs of containers. In this way, for example, a container system’s volumes, regardless of how numerous, can be managed one at a time, with each volume implemented using separate storage controllers and replicas, Liang says.




The key difference with Project Longhorn v0.2, besides Rancher’s above-mentioned claim that it combines all available local storage from all the nodes in a cluster, is it orchestrates storage controllers and replicas using Kubernetes. With Longhorn 0.2, the same Kubernetes will orchestrate both the application containers and the persistent volumes they use.
The net result is a complex block storage controller that can be partitioned into numerous smaller storage controllers, Liang says. Longhorn can offer 100,000 different storage controllers, replacing the need for a controller that would otherwise have to scale to 100,000 volumes. One of the effects is added resiliency, so a controller crash would only affect one volume.
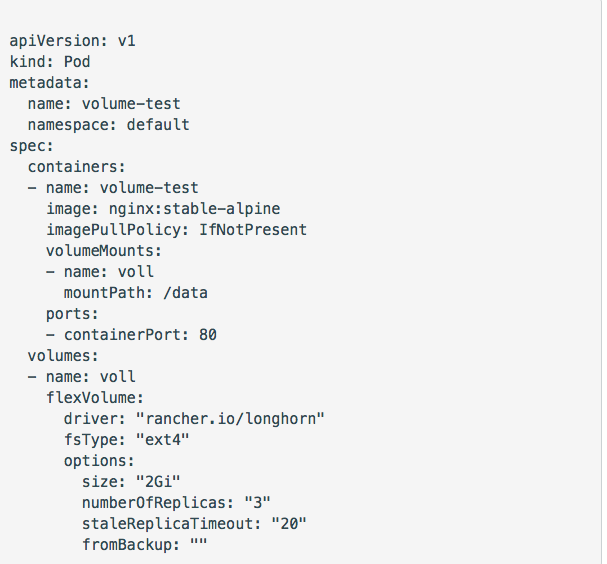
Deployment of Longhorn on a Kubernetes cluster involves just one command line of instructions. Commands for getting the proper IP address and creating a pod with a volume backing are also short and simple:
However, the Longhorn open source project remains a work in progress, especially considering the inherent difficulties of developing persistent storage with container systems.
A production version that allows users to replace high-end automated storage systems with persistent storage via Longhorn using Kubernetes is a long way off. Liang estimates the development stage of Longhorn is two to three years behind that of Rancher 2.0, which is set to launch as production-ready software this month.
A DevOps team is, thus, obviously not going to begin making the transition to switch its enterprise storage system to Longhorn in the near future. However, working through the bugs and exchanging information on the Longhorn forum or offering suggestions might be a pet project for someone on a DevOps team or for a technology enthusiast.
“Longhorn is technologically and intellectually interesting for someone to envision what storage implementation on containers could be like on Kubernetes in the future,” Liang says. “We obviously have our vision of why we are doing this. We will rely on what the open source community tells us.”
Already, for example, OpenEBS, which develops persistent and containerized block storage for DevOps and container environments, has begun to develop Longhorn as its underlying block storage system.
“As OpenEBS’ decision shows, there is a lot of interest in new storage technologies. As Longhorn matures, maybe folks will include it in their products,” Liang says. “Also, who’s to say that containers cannot be used to revolutionize storage implementations? That’s what Longhorn is really about.”